


 Widzenie komputerowe i detekcja obiektów są coraz częściej wykorzystywane w automatyzacji procesów biznesowych. Wraz z dynamicznym rozwojem technologii, zwłaszcza sztucznej inteligencji, pojawia się wiele nowych innowacyjnych aplikacji biznesowych dla tego typu algorytmów. W tym artykule pokażemy Ci, jak zrobić to z YOLO v5, które w ostatnich latach stało się bardziej popularne. Jednym z ważnych aspektów ponad innymi rozwiązaniami jest szybkość wnioskowania. W ramach tego artykułu przedstawimy określony przypadek użycia i wszystkie etapy jego realizacji. Życzymy miłej lektury!
Widzenie komputerowe i detekcja obiektów są coraz częściej wykorzystywane w automatyzacji procesów biznesowych. Wraz z dynamicznym rozwojem technologii, zwłaszcza sztucznej inteligencji, pojawia się wiele nowych innowacyjnych aplikacji biznesowych dla tego typu algorytmów. W tym artykule pokażemy Ci, jak zrobić to z YOLO v5, które w ostatnich latach stało się bardziej popularne. Jednym z ważnych aspektów ponad innymi rozwiązaniami jest szybkość wnioskowania. W ramach tego artykułu przedstawimy określony przypadek użycia i wszystkie etapy jego realizacji. Życzymy miłej lektury!

Studium przypadku
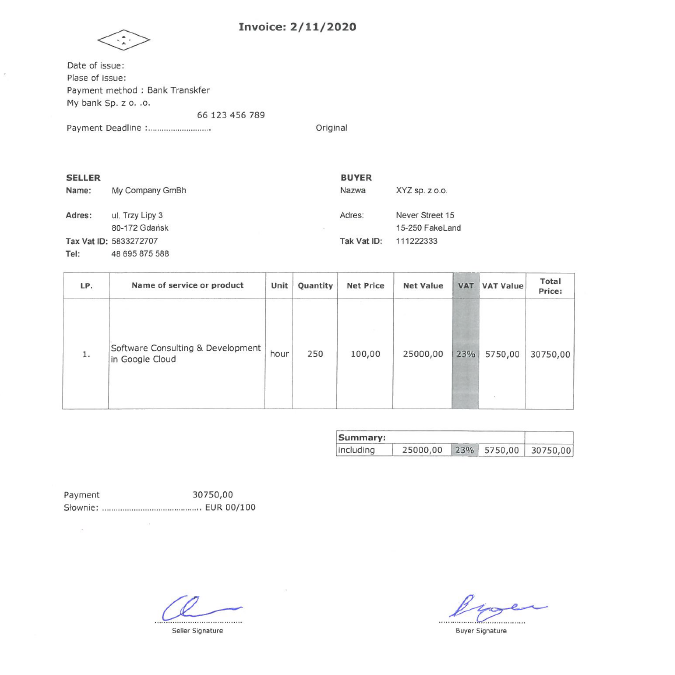
Podpisy są nadal jedną z najczęstszych metod uwierzytelniania dokumentów. Szczególnie w przypadku aplikacji korporacyjnych, identyfikacja podpisanych i niepodpisanych kopii dokumentów w repozytoriach cyfrowych może być czasochłonna i wymagająca. Jednak automatyzacja wspierana przez uczenie maszynowe może to ułatwić. W tym kontekście opiszemy możliwości detektora YOLO v5 oraz omówimy kwestie wykrywania podpisów na fakturach. Zacznijmy od przykładu pokazanego na poniższym rysunku. Na potrzeby tego badania przygotowaliśmy fałszywą fakturę, dane sprzedawcy, kupującego i samego produktu. Zbadajmy teraz, jak możemy skupić się na odręcznych podpisach (które też są fałszywe).
Zbieranie danych
Jednym z pierwszych kroków jest zebranie zestawu obrazów do trenowania modelu. Dla naszego przypadku przygotowaliśmy mały zestaw 10 przykładowych szkoleń z fakturami wypełnionymi różnymi danymi i rozszerzyliśmy ten zbiór o dedykowany skrypt w języku Python. Aby to ułatwić, użyliśmy Roboflow, który jest przydatnym narzędziem do tagowania danych. Tutaj możesz przesłać swój zbiór danych i wykonać szybki proces dodawania adnotacji, dokładnie jak na tym GIF-ie.
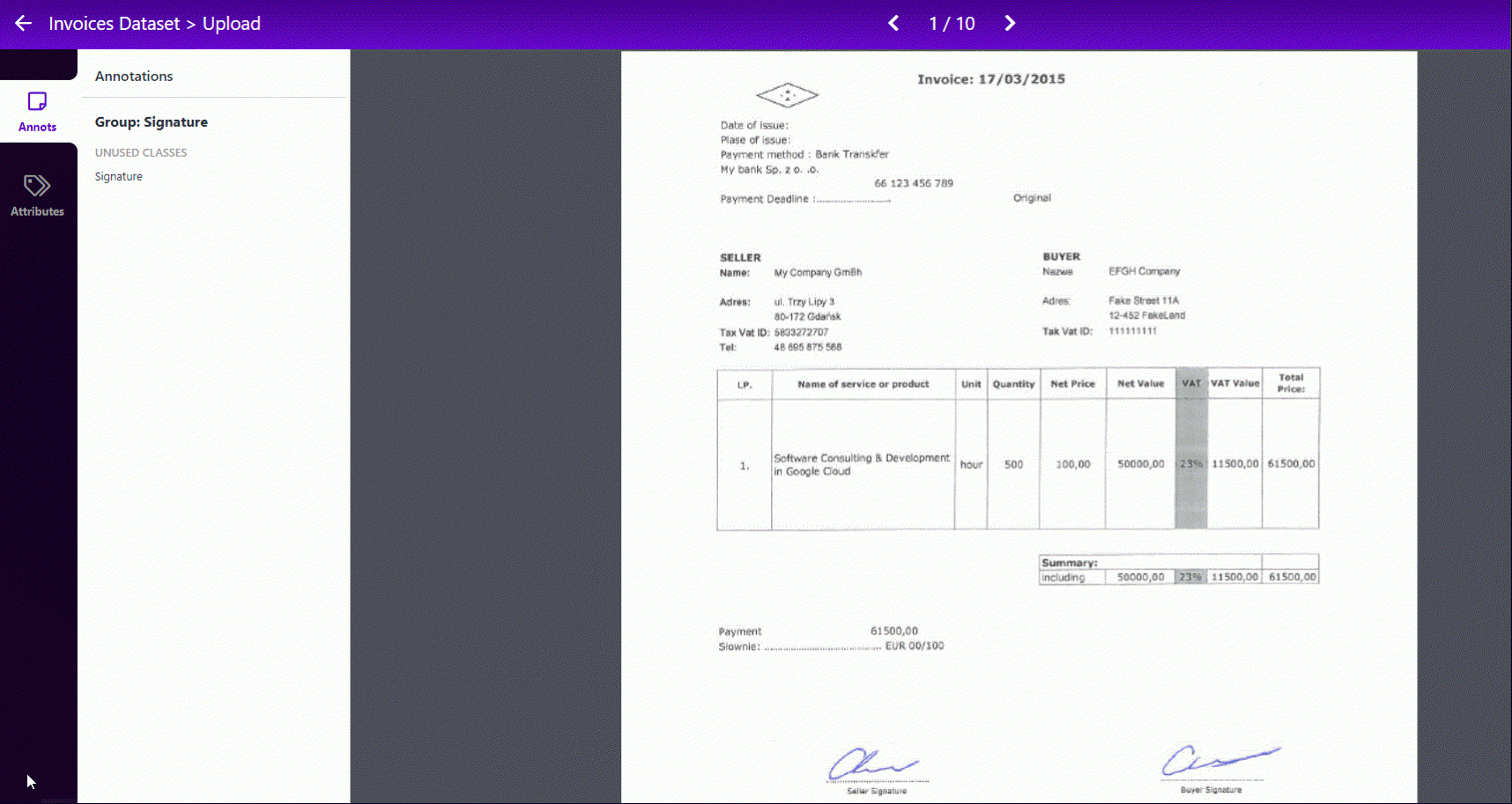
Dodatkowo możemy wygenerować więcej obrazów wyjściowych z losowymi wartościami obrotu, nasycenia, ekspozycji, szumu, rozmycia i innego rodzaju przekształceń. Co więcej, za pomocą tego narzędzia możemy określić nasz podział danych treningowych, walidacyjnych i testowych – domyślnie 70%, 10%, 10%. Jest to ważne, ponieważ dzięki temu zapobiegniemy przesunięciu naszego modelu (więcej o tym dowiesz się na tym blogu). Dzięki opisanemu narzędziu możemy wyeksportować nasz zbiór danych w formacie YOLO v5 Pytorch i umieścić go w katalogu naszego projektu. Poniższy rysunek przedstawia drzewo selekcji i drzewo docelowe, gdzie jednym z najważniejszych plików jest data.yml, który zostanie użyty do uczenia.
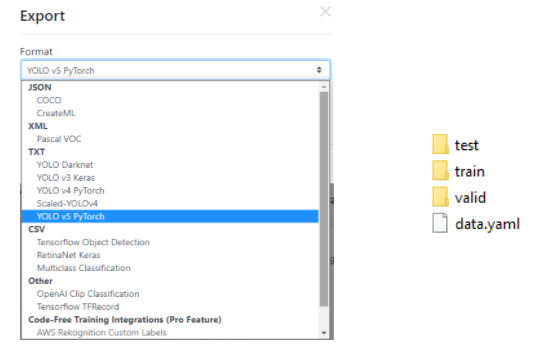
W naszym przypadku po pierwszym kroku augmentacji o skrypt Pythona generujemy 69 obrazów. Dodatkowo używamy opcji szumu w Roboflow, która pozwala nam ostatecznie wyeksportować 169 przykładów z adnotacjami. Nasze obrazy zostały ostatecznie podzielone, jak pokazano na poniższym rysunku.

Poniżej możesz zobaczyć kilka przykładów:

Konfiguracja i architektura modelu
Kolejnym krokiem w tym procesie jest zdefiniowanie konfiguracji i architektury modelu YOLO. Możemy zbudować własną strukturę sieciową, chociaż w wersji 5 mamy do dyspozycji jeden z następujących modeli:
- YOLOv5s,
- YOLOv5m,
- YOLOv5l,
- YOLOv5x.
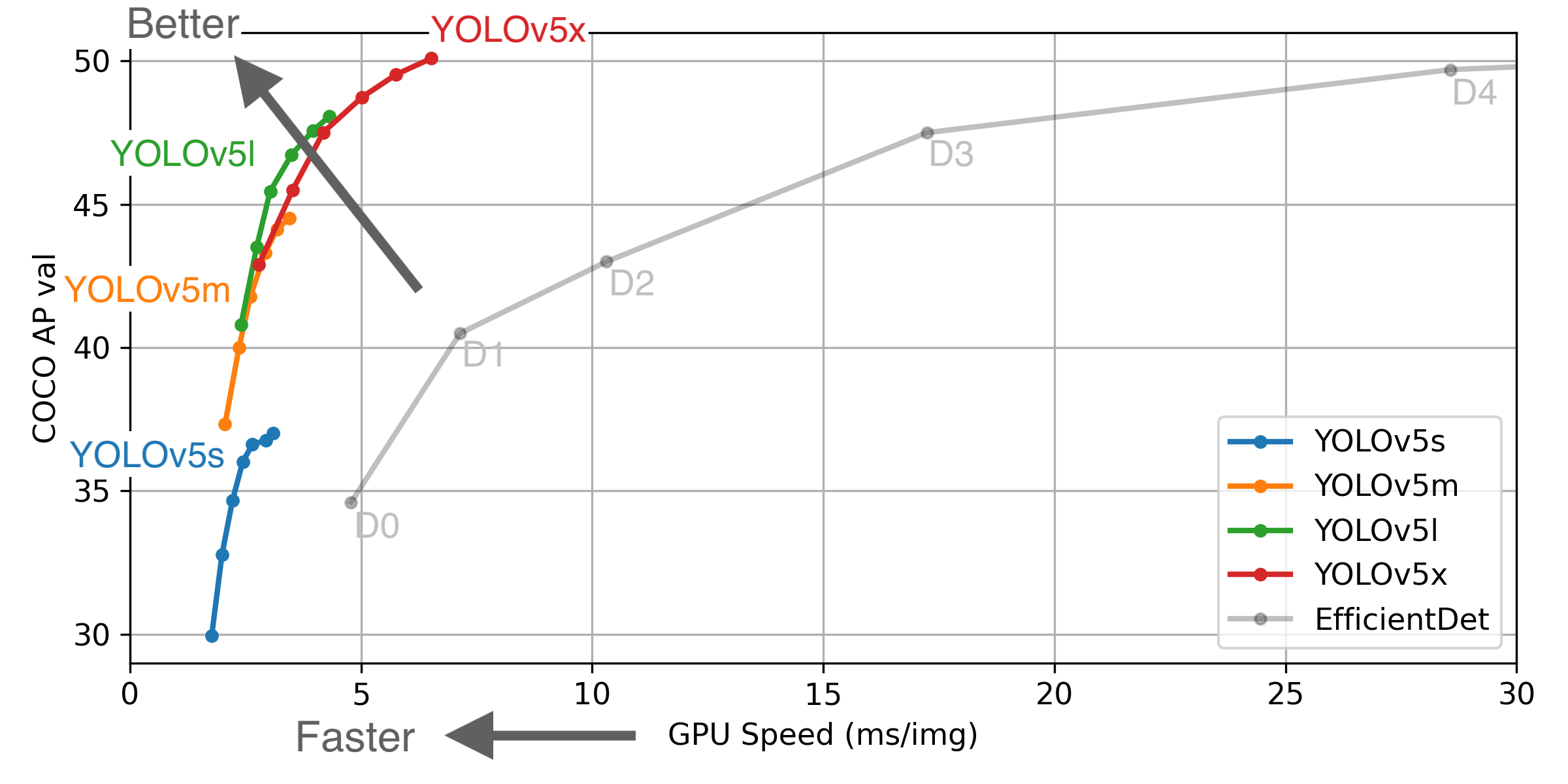
Możemy użyć dowolnego z nich, ale pamiętajmy o przypisaniu do pliku docelowego odpowiedniej wartości parametru zwanej nc – liczba klas. W naszym przypadku jest to 1. Modele różnią się między sobą ilością użytych parametrów, szybkością klatek na sekundę (FPS), dokładnością itd.. Na poniższym rysunku widać, jak radzą sobie one z tym samym zbiorem danych COCO. Kliknij na obrazek, aby dowiedzieć się więcej.

Szkolenie
Co ważne, firma Ultralytics udostępnia nam YOLO v5 opracowany w PyTorch. Jest to framework wyspecjalizowany w uczeniu maszynowym. Dzięki temu możemy pobrać ich repozytorium z GitHub i wyszkolić własny detektor. Czego jeszcze potrzebujemy, aby wszystko działało dobrze?
Aby uruchomić każdy ze skryptów musimy zainstalować zależności zawarte w pliku requirements.txt. Jeśli używamy pip, możemy użyć następującego polecenia w terminalu. Pamiętaj, że musisz znajdować się w katalogu projektu.
pip install -r requirements.txt
W procesie instalacji problemem może być jedna rzecz. Mianowicie biblioteka PyTorch…
Inny system operacyjny, używany pakiet, język programowania itp. mogą wymagać określonego polecenia. W tym samouczku znajdziesz wszystko, czego potrzebujesz.
Załóżmy, że spełniłeś wszystkie wymagania. Możesz już rozpocząć szkolenie!
Do uruchomienia tego procesu wystarczy jedna linijka kodu, ale musimy się upewnić, że przygotowaliśmy dwa ważne pliki – data.yaml i np. yolov5l.yaml. Pierwszą powinieneś mieć z etapu zbierania danych, a drugą znajdziesz w repozytorium YOLO v5, w katalogu Models.
Przeprowadźmy szkolenie następującą komendą:
python train.py --data dataset/data.yaml --cfg models/yolov5l.yaml --weights ''
Powyższe polecenie jest najprostsze z możliwych. Dodatkowo można zdefiniować następujące opcje lub parametry:
- img-size,
- batch-size,
- epochs,
- name,
- no-save,
- cache…
Na potrzeby tego artykułu przeprowadziliśmy stosunkowo krótkie szkolenie dla obrazów o rozmiarze zmienionym do 416×416, wielkości partii 32 i 1500 epok. Po zakończeniu procesu wynikiem będzie plik o nazwie best.pt.
Możesz przerwać proces uczenia się, jeśli w danym momencie Twoje wagi są dla Ciebie optymalne. Szkolenie przerwaliśmy po 650 epokach, co w sumie trwało około 15 godzin. Trzeba pamiętać, że używany komputer nie posiada dedykowanej karty graficznej.

Szczegółowe metryki naszego szkolenia:
- precision – 0.93507,
- recall – 0.96429,
- mAP_0.5 – 0.94755,
- mAP_0.5:0.95 – 0.48702,
gdzie:
precision – mierzy, jak trafne są Twoje przewidywania,
recall – mierzy, jak dobrze oceniasz wszystkie pozytywy,
mAP_0.5 – średnia precyzja dla IoU* – 0,5
mAP_0.5:0.95 – średnia precyzja dla IoU* od 0,5 do 0,95 z krokiem 0,005,
* IoU (Intersection over Union) – mierzy nakładanie się dwóch granic. Dowiedz się więcej o wskaźnikach tutaj.
Wnioskowanie
Teraz, możemy przejść do wnioskowania na obrazach testowych. Jak pamiętasz, jeden z katalogów wyeksportowanych z Roboflow nazywał się test. Możemy z niego skorzystać, wstawiając w terminalu następującą linię.
python detect.py --weights best.pt --source dataset/test --conf 0.6 --img-size 600
gdzie conf jest ufnością modelu – wyższy oznacza mniej przewidywań.
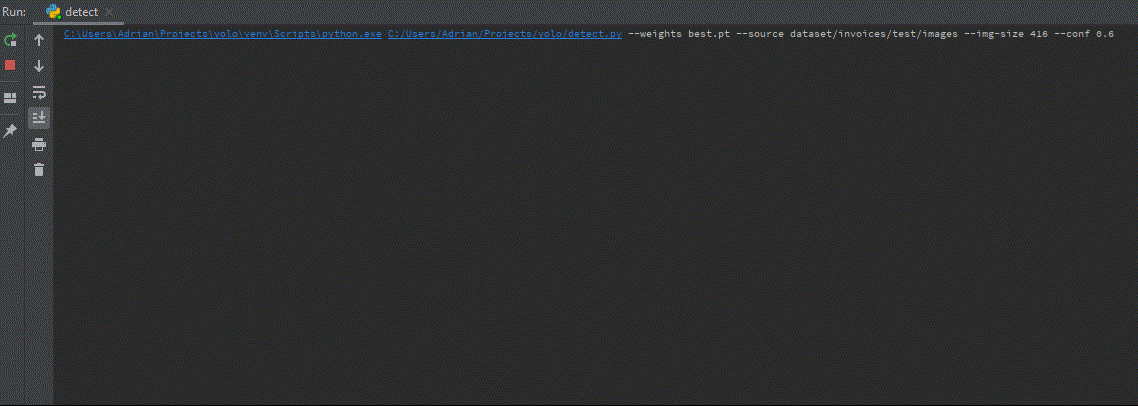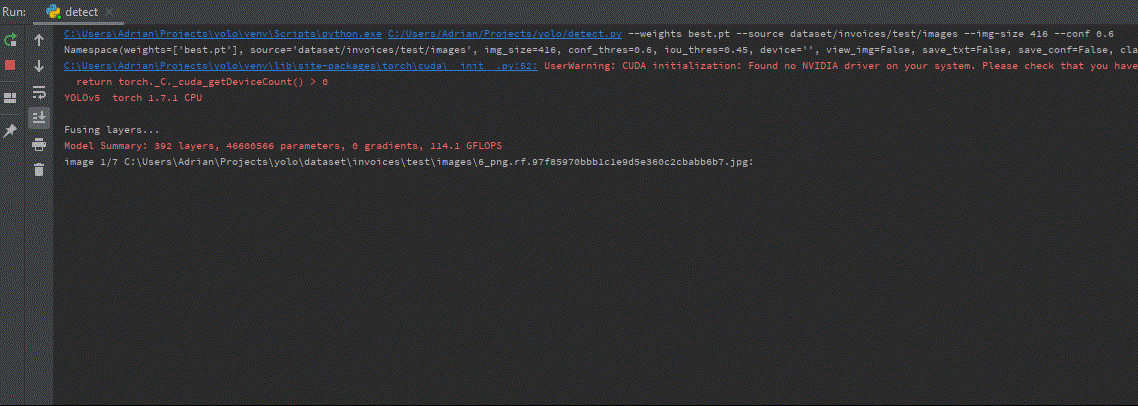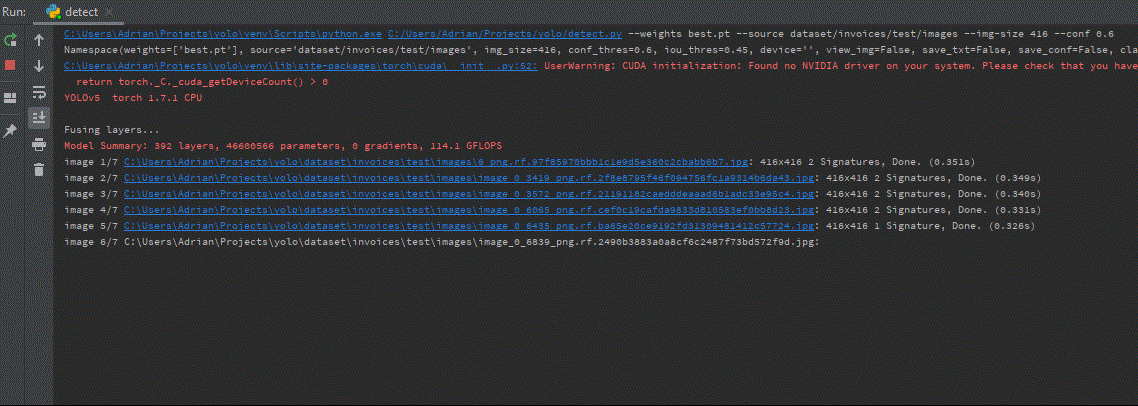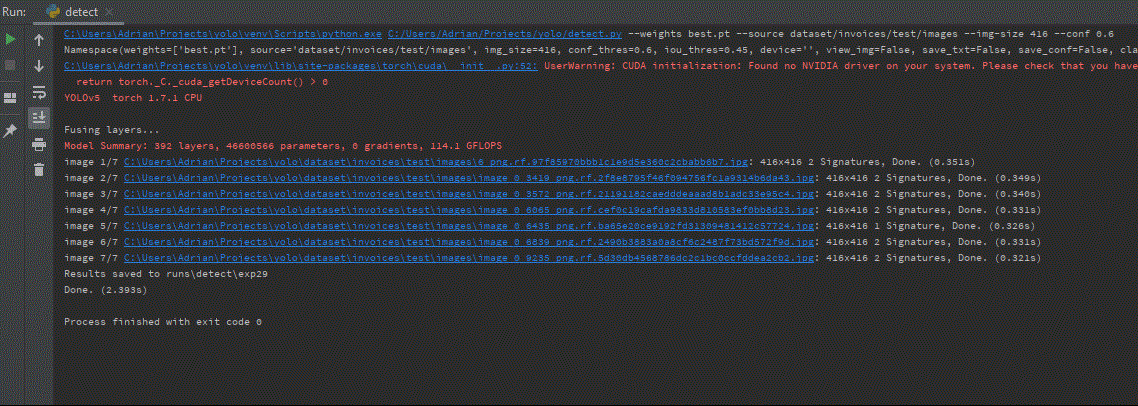
Na koniec możemy zobaczyć wizualizację wyniku. Przybliżony czas wnioskowania na jednym obrazie testowym 416×416 wyniósł ~0,3s, natomiast dla 700×700 ~0,8s.

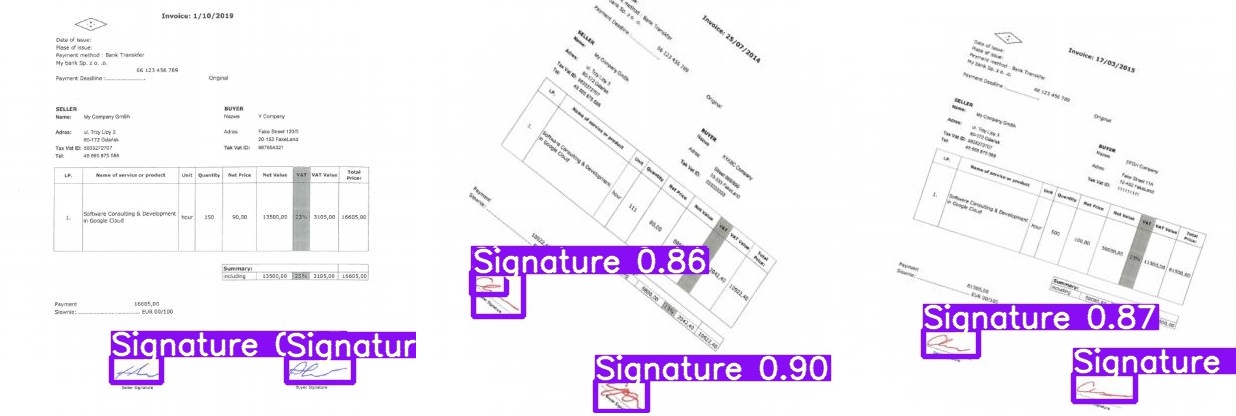

Podsumowanie
Do implementacji opisywanego detektora wykorzystaliśmy tylko 10 obrazów, rozszerzając zbiór danych o proces augmentacji. Dzięki narzędziu Roboflow możliwe było szybkie opisywanie i eksportowanie danych do formatu YOLO. Proces uczenia pozwolił nam uzyskać detektor celu, który skutecznie rozpoznaje podpisy na fakturach.
Należy pamiętać, że przy tak małym zbiorze danych jest on przystosowany tylko do rozpoznawania podobnych faktur. Gdybyśmy chcieli rozszerzyć możliwości naszego detektora, musielibyśmy wyposażyć się w lepszą kartę graficzną i więcej danych.
Inero Software oferuje wiedzę i doświadczenie w zakresie skutecznego wykorzystywania najnowocześniejszych technologii i danych do kształtowania korporacyjnych produktów cyfrowych przyszłości.
Aby uzyskać więcej informacji, odwiedź nas na naszej stronie internetowej lub śledź nas na LinkedIn.