



Budowa systemu rozpoznawania komend głosowych w języku polskim
 System rozpoznawania komend głosowych został stworzony po to, aby usprawnić życie człowieka. Pełni on rolę pomocnika, który wyszuka dla nas odpowiednie informacje, ułatwi zakupy w Internecie czy umożliwi obsługę różnych urządzeń bez wykorzystywania zewnętrznych przycisków czy regulacji. Jednak stworzenie takiego systemu od podstaw może być trudnym wyzwaniem. W szczególności, jeśli chcemy zbudować go w języku polskim.
System rozpoznawania komend głosowych został stworzony po to, aby usprawnić życie człowieka. Pełni on rolę pomocnika, który wyszuka dla nas odpowiednie informacje, ułatwi zakupy w Internecie czy umożliwi obsługę różnych urządzeń bez wykorzystywania zewnętrznych przycisków czy regulacji. Jednak stworzenie takiego systemu od podstaw może być trudnym wyzwaniem. W szczególności, jeśli chcemy zbudować go w języku polskim.
Istnieją ogólne modele sieci neuronowych, które dedykowane są rozpoznawaniu języka mówionego, czyli transkrypcji nagrania audio do tekstu. Wszystko jednak uwarunkowane jest od tego, ile danych posiadamy. Obecnie istnieje wiele zbiorów nagrań z języka angielskiego, które są odpowiednio przygotowane. Same dane jednak nie wystarczą. Muszą być do nich dołączone transkrypcje. Niestety w języku polskim nie mamy dużej ilości próbek głosowych razem z transkrypcjami. Na dzień dzisiejszy nie jesteśmy więc w stanie tak dobrze wyuczyć modeli, jak to jest robione w języku angielskim.
Jak na razie nie możemy wyuczyć asystentów wykorzystując modele open source’owe z zadowalającą skutecznością, jednak możemy sprawdzić co jesteśmy w stanie zbudować z ogólnie dostępnych danych. Celem naszej pracy jest stworzenie systemu rozpoznawania mowy, który działa w ograniczonym zbiorze komend.
Główne źródła zbierania danych dla systemu rozpoznawania komend głosowych
W ostatnich miesiącach pojawiły się zbiory danych: Common Voice i Zasoby Nauki, które są odpowiednio przygotowane pod modele ASR (Automatic Speech Recognition). Oznacza to, że nagrania dźwiękowe zawierają również transkrypcje. Są to tak naprawdę dwa największe zbiory danych, które można użyć. Do zbudowania własnego systemu wykorzystaliśmy więc je i złączyliśmy w jedno.
Common Voice jest ciekawym zbiorem danych. Jeżeli chcemy aby ich ilość była jeszcze większa, możemy kontrybuować w tym działaniu. Każdy z nas może wejść na stronę i nagrać swój głos, który zostanie zapisany, a następnie sprawdzony przez innych użytkowników. W ten sposób będziemy mogli przyczynić się do powiększenia ilości danych z języka polskiego, dzięki czemu budowanie systemów rozpoznawania komend głosowych będzie łatwiejsze.
W przyszłości istnieje możliwość, że YouTube udostępni do wykorzystania swoje nagrania audio razem z automatycznie generowanymi transkrypcjami. Jest to jednak rozwiązanie, które (być może) powstanie dopiero później. Dodatkowym źródłem danych mogą również być audiobooki, które zawierają transkrypcję książek i nagrania audio. W takim przypadku musimy jednak wykonać pracę przygotowania danych polegającą na pofragmentowaniu danych na krótsze nagrania. Dodatkowo zmienna intonacja lektora może wpływać na dokładność wyuczonych przez nas modeli.
Przygotowanie i ujednolicenie danych
Przede wszystkim musimy zapewnić minimalną i maksymalną długość nagrania. Muszą one znajdować się w określonych ramach czasowych. Zbyt długie nagrania mogą być problemem podczas uczenia modelu, natomiast krótkie nagrania mogą nie nieść ze sobą żadnej istotnej informacji. Musimy także zapewnić jednakową częstotliwość próbkowania sygnału. Jest to bardzo ważna kwestia przy uczeniu modeli opartych na dźwięk.
Fala dźwiękowa czystego tonu, rozchodząca się w przestrzeni, ma charakter sinusoidalny. Zmiana częstotliwości takiego dźwięku oznacza zmianę okresu sinusoidy, więc zmieniają się odległości między jej grzbietami. Jednak dźwięk w komputerze również musi być w jakiś sposób zaprezentowany. Sinusoida jest przebiegiem ciągłym, natomiast komputer zapisuje pojedyncze wartości. Częstotliwość próbkowania mówi nam o tym, ile razy na sekundę została zapisana wartość rejestrowanej fali dźwiękowej. Bardzo ważne jest to, żeby każdy dźwięk, który wchodzi do naszego modelu miał taką samą częstotliwość próbkowania.
Poprzez nieprawidłowe próbkowanie rekonstruowany dźwięk może być zniekształcony lub całkowicie niesłyszalny. Trzeba więc pamiętać o odpowiednim dobraniu częstotliwości próbkowania, aby zminimalizować rozmiar zapisywanych danych przy jednoczesnym braku utraty informacji. Zbyt rzadkie próbkowanie może spowodować pojawienie się zjawiska aliasingu, czyli nakładania się wyższych częstotliwości na niższe.
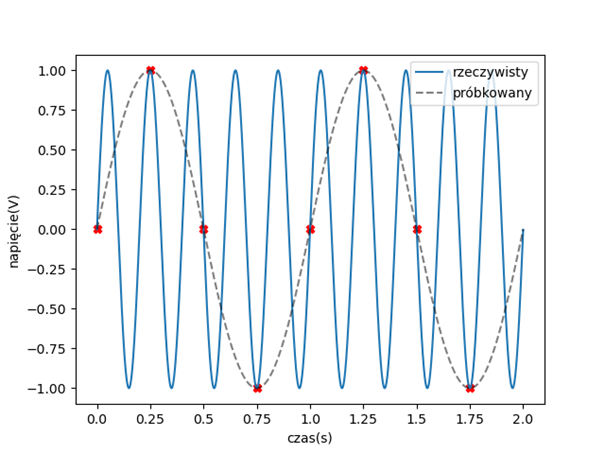
Źródło: Reprezentacje danych dźwiękowych w kontekście metod uczenia maszynowego, s. 134, Tymoteusz Cejrowski
Zapobieganie takiemu zjawisku polega na próbkowaniu sygnału z częstotliwością co najmniej dwa razy większą od najwyższej częstotliwości występującej w sygnale. Częstotliwość ta nazywana jest częstotliwością Nyqiusta. Dla przykładu, nagrania na płytach CD są zapisywane z częstotliwością próbkowania 44100 Hz. Natomiast maksymalna poprawnie zrekonstruowana częstotliwość będzie wynosiła 22050 Hz, co odpowiada górnemu zakresowi dźwięków słyszalnych przez człowieka.
Opis i uczenie modelu deepspeech w systemie rozpoznawania komend głosowych
![]()
![]() Sieci neuronowe w pewien sposób przypominają układ nerwowy. Podstawowymi jednostkami w takich sieciach są neurony, które rozmieszczone są w warstwach. Jest to uproszczony model procesu przetwarzania informacji przez ludzki umysł.
Sieci neuronowe w pewien sposób przypominają układ nerwowy. Podstawowymi jednostkami w takich sieciach są neurony, które rozmieszczone są w warstwach. Jest to uproszczony model procesu przetwarzania informacji przez ludzki umysł.
Zazwyczaj sieć neuronowa składa się z trzech części. Pierwsza to warstwa wejściowa, która posiada jednostki reprezentujące zmienne wejściowe. Następna część to warstwy ukryte, które zawierają jednostki nieobserwowane i są ukrytym stanem sieci neuronowej. To właśnie od tych warstw w dużej mierze zależy efektywność modelu. Natomiast ostatnią częścią jest oczywiście warstwa wyjściowa, która posiada jednostki reprezentujące zmienne przewidywane. Wszystkie jednostki złączone są konkretnymi połączeniami o różnej wadze. Dane wejściowe znajdują się na pierwszej warstwie, przechodzą one przez kolejne, a ostatecznie z warstwy wyjściowej otrzymujemy wynik.
Sieć neuronowa uczy się przez porównywanie rekordów. Generuje ona predykcje dla konkretnych danych (nagrań audio) i wprowadza korekty wag, jeśli generują one niepoprawną predykcję (złą transkrypcję). Cały proces powtarzany jest wiele razy do uzyskania satysfakcjonującej dokładności. Wszystkie wagi na początku mają charakter losowy, a odpowiedzi wychodzące nie mają dużo sensu, z czasem natomiast sieć poprawia swoje predykcje. Dzieje się tak, ponieważ sieć dopasowuje się do danych w procesie uczenia wykorzystując algorytm wstecznej propagacji błędu.
Jednym z najprostszych modeli Sieci Neuronowych jest Perceptron wielowarstwowy. Składa się on z wielu warstw neuronowych. Neurony poprzedniej warstwy tworzą konkretny wektor, który jest podawany na wejście neuronów do warstwy następnej. Pojedynczy neuron w warstwie następnej ma liczbę wejść równej liczbie neuronów z warstwy poprzedniej +1. Jednak w ramach jednej warstwy, neurony między sobą nie mają żadnych połączeń. Taki typ modelu nazywany jest również modelem „Feed-Forward” i jest jedną z podstawowych architektur sieci neuronowych.
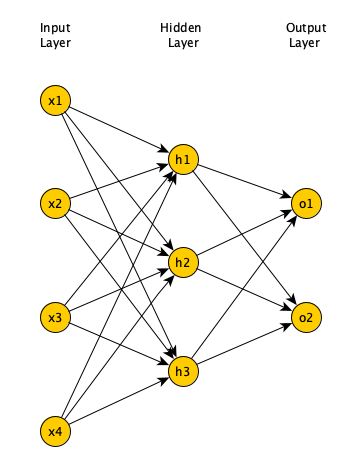
Rysunek przedstawiający model „Feed-Forward”
Sieci rekurencyjne różnią się od sieci typu „Feed-Forward” w wielu aspektach. Jedną z głównych różnic jest sposób propagacji danych wejściowych na wyjście sieci. W najprostszym modelu wyjście sieci jest niczym innym kombinacją wag i wejścia modelu (pojedynczego rekordu). W przypadku sieci rekurencyjnych wyjście modelu zależy również od poprzedniego wyjścia. Wynik działania modelu dla rekordu X jest brany pod uwagę przy wyliczaniu wyjścia dla kolejnego rekordu Y.
Konwolucyjna sieć neuronowa jest typem sieci najczęściej stosowanej do analizy obrazów wizualnych z uwagi na swój charakter procesowania wejścia. Podobnie jak człowiek, sieć ta nie analizuje obrazu piksel po pikselu ale wyłapuje wzorce obecne w danych wejściowych dzięki zastosowaniu tzw. Kerneli czyli filtrów. Każda warstwa w sieci neuronowej uczy się cech obrazu takich jak kontury czy nasycenie światłem. Złożenie tych informacji poprawia efektywność modelu.
Poza neuronowymi modelami rozpoznawania mowy, warto pochylić się nad open source’owymi systemami, które umożliwiają zbudowanie systemu rozpoznawania komend głosowych. Jednym z nich jest Kaldi, który został napisany w C++. Powstał on w 2009 roku, a jego głównymi cechami jest to, że system ten jest rozszerzalny i cały czas rozwijany. Udostępnia on m.in. narzędzia do pre-procesowania nagrań audio czy modeli opartych o Ukryte Modele Markowa (HMM). Sama społeczność udostępnia wiele innych modułów, które można wykorzystać do własnych zadań. Kaldi, poza modelami statystycznymi, obsługuje także głębokie sieci neuronowe. Pomimo tego, że jest napisany głównie w C++, to posiada on skrypty w jezyku Bash czy Python.
W naszej pracy skupiliśmy się jednak na konkretnym modelu ASR: deepspeech 2. Jest to model, który wykorzystuje głębokie uczenie (ang. Deep Learning), składa się on z 3 warstw konwolucyjnych, 8 rekurencyjnych i jednej Fully-Connected. Deepspeech 2 można z powodzeniem wyuczyć na dowolnym języku, trzeba jednak pamiętać, że takie uczenie wymaga wydajnego systemu komputerowego/serwerowego wyposażonego w odpowiednią ilość kart graficznych lub akceleratorów obliczeń.
W przypadku popularnych języków takich jak angielski czy mandaryński można znaleźć przetrenowane modele gotowe do użycia. W naszym zadaniu wybraliśmy deepspeech 2 z implementacją w PyTorchu, ponieważ jest on lekki, ma stosunkowo mało parametrów (wag do wyuczenia) i wybrana przez nas implementacja jest aktywnie utrzymywana. W tym modelu oprócz przygotowania odpowiednich częstotliwości próbkowania o których pisaliśmy wyżej, musieliśmy również przygotować odpowiednio dane pod sam model deepspeech. Wiązało się to z zapewnieniem odpowiedniej struktury katalogów.
Wnioskowanie z użyciem modeli ASR i dodatkowego modelu językowego
Wykorzystując deepspeech jesteśmy w stanie zastosować dodatkowy model językowy (model n-gramowy). Opiera się on na statystykach i pomaga w przewidywaniu kolejnego elementu sekwencji w wynikowej transkrypcji. Trzeba pamiętać, że zastosowanie takiego modelu wymaga zgromadzenia dużego zasobu danych statystycznych. N-gramy pomagają maszynom w zrozumieniu słowa w konkretnym kontekście. Dzięki temu mogą one lepiej zrozumieć jego przeznaczenie.
Jeśli chcemy utworzyć taki model, zaczynamy od zliczania wystąpień sekwencji o ustalonej długości n w istniejących już zasobach językowych. Analizuje się więc całe teksty i zlicza się pojedyncze wystąpienia (1-gram), dwójki (2-gramy) i trójki (3-gramy). Możemy również uzyskać model 4-gramowy, jednak tutaj potrzebne są już ogromne zbiory danych, przez co dla języka polskiego jest to niezwykle trudne do zrealizowania. W kolejnym kroku zamienia się liczbę wystąpień na prawdopodobieństwo poprzez normalizację. W ten sposób zyskujemy predykcję kolejnego elementu na podstawie dotychczasowych sekwencji. Warto zaznaczyć, że im więcej przeanalizowanego tekstu, tym wyższa jakość modelu. Dane te są głównie wykorzystywane w aplikacjach przetwarzania języka naturalnego (NLP). Model n-gramowy dla języka polskiego można znaleźć tutaj.
Użycie modelu n-gramowego na etapie wnioskowania pozwala na skorygowanie wyjścia sieci neuronowej (transkrypcji modelu deepspeech 2) zgodnie z regułami zawartymi w modelu n-gramowym.
Działanie w ograniczonym zbiorze komend
Niestety budowane modele nie mogą być wystarczająco dokładne ze względu na małą ilość danych w języku polskim. W naszym przypadku możemy jednak działać w ograniczonym zbiorze komend. Oznacza to, że rozpoznawaniu podlega konkretna ilość komend głosowych. Nasze zadanie polegało na tym, żeby dopasować odpowiednią komendę ze zbioru z tym co dostarczył nam model. Ważne jest tutaj określenie najwyższego podobieństwa pomiędzy komendą, a tym co zwrócił nam model.
Do tego zadania wykorzystaliśmy miarę zwaną odległością Levenshteina, która wskazuje na podobieństwo pomiędzy transkrypcją, a daną komendą. Polega ona na zliczaniu pozycji lub liter, które się nie zgadzają. Przykładowo, odległość Levenshteina pomiędzy wyrazami:
- drzwi
- drzwi
Jest zerowa. Są to wyrazy identyczne, więc nie potrzeba tutaj żadnych działań.
Natomiast odległość Levenshteina pomiędzy wyrazami:
- kołacz
- połać
wynosi 3, ponieważ potrzeba co najmniej 3 działań: zamiany k na p, zamiany c na ć i usunięcia litery z.
Tam, gdzie jest najmniej podstawień, posiadamy największe prawdopodobieństwo, że komendy są takie same.
Podsumowanie
Celem systemów rozpoznawania głosu jest zapewnienie łatwości w komunikacji między urządzeniem a człowiekiem. Podejście wykorzystujące narzędzia Open-Source w zadaniu uczenia modeli ASR na razie ogranicza się do rozpoznawania ograniczonego zbioru komend. Budowanie takiego sytemu w oparciu o dane w języku polskim jest trudnym zadaniem, ze względu na małą ilość danych dźwiękowych połączonych z transkrypcjami. Zastosowanie miary podobieństwa pomiędzy transkrypcją a zbiorem komend pozwala na zbudowanie użytecznego systemu ASR działającego w trybie offline. Biorąc pod uwagę aktualne trendy w wykorzystaniu inteligentnych urządzeń oraz możliwości techniczne, warto obserwować dalszy rozwój tych systemów i pojawiające się nowe zbiory danych.
Inero Software oferuje wiedzę i doświadczenie w zakresie skutecznego wykorzystywania najnowocześniejszych technologii i danych do kształtowania korporacyjnych produktów cyfrowych przyszłości.
W sekcji BLOG można znaleźć inne artykuły dotyczące nowoczesnych rozwiązań dla przedsiębiorstw.
Redakcja: Tymoteusz Cejrowski, Software Developer.