



How to build your own custom voice command recognition system?
 The concept of voice assistant was created to improve human life. It plays the role of an tool which will find appropriate information for us, facilitate online shopping or manage the operation of various devices without any pressing or regulating. However, creating such a system from scratch can be a difficult challenge. Especially if we want to build it in language other than english.
The concept of voice assistant was created to improve human life. It plays the role of an tool which will find appropriate information for us, facilitate online shopping or manage the operation of various devices without any pressing or regulating. However, creating such a system from scratch can be a difficult challenge. Especially if we want to build it in language other than english.
There are general models of neural networks that are dedicated to spoken language recognition, i.e. transcription from audio to text. Everything depends on how much data we have. Nowadays, there are many recordings of the English language that are decently prepared. However, data alone is not enough. Transcripts must be attached to them. Unfortunately, in Polish we do not have a many voice samples with transcripts. So today we are not able to teach models as well as it is done in English.
So far, we cannot train assistants using open source models with satisfactory effectiveness, but we can check what we are able to build from generally available data. The goal of our work is to create a speech recognition system that actually works.
Preparation and standardization of data for voice command recognition system
First, we need to ensure the minimum and maximum length of the recording. They must be within a certain time frame. Long recording may be a problem when training the model, while short recording may not carry any relevant information. We also need to ensure that the signal is sampled at the same rate. This is an important point when we are teaching sound based models.
A pure tone sound wave propagating in space is sinusoidal. Changing the frequency of such a sound means a change in the period of the sinusoid, so the distances between its crests change. However, the sound in the computer also has to be presented in some way. The sine wave is continuous and the computer stores individual values. The sampling rate tells us how many times per second the value of the sound wave was recorded. It is important that each sound that enters our model has the same sampling rate.
Due to incorrect sampling the reconstructed sound can be distorted or completely inaudible. Therefore, it is necessary to remember about the appropriate selection of the sampling frequency to minimize the size of the saved data with the simultaneous lack of information loss. Sampling too rarely can cause aliasing, i.e. the overlap between higher frequencies and lower frequencies. For example, a sound that is a mechanical sinusoidal wave with a frequency of 3 Hz may be misinterpreted as a lower frequency signal. This situation is presented in the figure below, in which a sinusoidal signal with a frequency of 5 Hz was interpreted as a signal with a frequency of 1 Hz due to a too low sampling frequency.
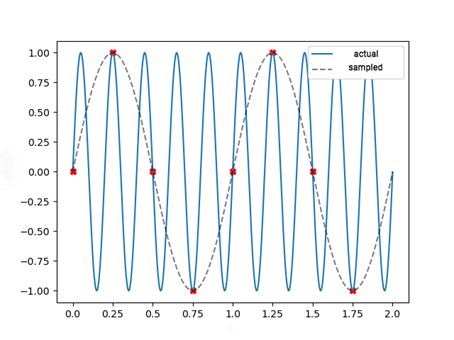
Source: Reprezentacje danych dźwiękowych w kontekście metod uczenia maszynowego, Tymoteusz Cejrowski
This is prevented by sampling the signal at a frequency of at least twice the highest frequency in the signal. This is called the Nyquist frequency. For example, recording on CDs are saved at a sampling rate of 44100 Hz. On the other hand, the maximum correctly reconstructed frequency will be 22050 Hz, which corresponds to the upper range of sounds audible by humans.
Description and teaching of the deepspeech model
![]()
![]() Neural networks are somewhat like the nervous system. The basic units in such networks are neurons, which are arranged in layers. It is a simplified model of information processing by the human mind.
Neural networks are somewhat like the nervous system. The basic units in such networks are neurons, which are arranged in layers. It is a simplified model of information processing by the human mind.
Typically, a neural network consists of three parts. The first is the input layer which has units representing the input variables. The next part is the hidden layers that contain the unobserved entities and are the hidden state of the neural network. It is on these layers that the efficiency of the model largely depends. The last part, of course, is the output layer, which has units representing the targets. All interconnected units are specific connections of different weights. The input data is on the first later, it goes through the next layer, and finally we get the result from the output layer.
The neural network can learn by comparing records. It generates predictions for specific data (audio recordings) and introduces weights adjustments if the generate an incorrect prediction (wrong transcription). The whole process is repeated many times until the accuracy is satisfactory. All weights are random at first and outgoing responses don’t make such sense, while the network improves its predictions over time. This is because the network adapts to the data as it learns.
One of the simplest models of Neural Networks is the Multilayer Perceptron. It consists of many neural layers. The neurons of the previous layer form a specific vector that is fed to the entry of neurons into the next layer. A single neuron in the next layer has the number of inputs equal to the number of neurons in the previous layer +1. However, within one layer, the neurons do not have any connections with each other. This type of model is also known as the “Feed-Forward” model and is one of the fundamental architectures of neural networks.
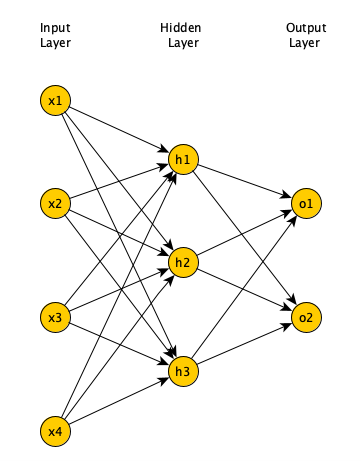
Figure representing the “Feed-Forward” model.
Recursive networks differ from Feed-Forward networks in many respects. One of the main differences is how the input data is propagated to the output of the network. In the simplest model, the network output is nothing but a combination of weights and the model input (single record). For recursive networks, the model output also depends on the previous output. The result of the model operation for the X record is taken into account when calculating the output for the next Y record.
A convolutional neural network is the type of network most commonly used for visual image analysis due to its input processing nature. Like a human, this network does not analyse the image pixel by pixel, but captures the patterns present in the input thanks to the use of the so-called Kernels or filters. Each layer in the neural network learns image characteristics such as contours and light saturation. Submitting this information improves the efficiency of the model.
However, it is worth looking at open source systems that enable the creation of voice command recognition. One of them is Kaldi, which was written in C++. It was created in 2009 and its main features are that the system is extensible. The community itself provides many other modules that you can use for your own tasks. Kaldi also supports deep neural networks. Although it is written mainly in C++, it has Bash and Python scripts.
For the construction of the voice command recognition system, we focused on the deepspeech 2 model. It uses deep learning and it consists of 3 convolutional layers, 8 recursive layers and one Fully-Connected (described as Feed-Forward). Deepspeech 2 can be successfully trained in any language, but you have to remember that models are most often issued only with code, so you have to learn them yourself. For popular languages such as English and Mandarin, there are pre-trained ready-to-use models. For our assignment, we chose deepspeech 2 with a PyTorch implementation because it is lightweight, relatively few parameters (weights to learn), and is actively maintained. In this model, in addition to preparing the appropriate sampling frequencies about which we wrote above, we also had to prepare the data for the deepspeech model itself. This was related to the provision of an appropriate directory structure.
Reasoning with the use of ASR models and an additional language model
Using deepspeech we are able to apply an additional language model (n-gram model). It is based on statistics and helps predict the next element in the sequence. It must be remembered that the application of such a model requires the collection of a large amount of statistical data. N-grams help machines understand a word in a specific context. This allows them to understand its purpose better. So if you want to build an effective voice command recognition system, it is worth considering.
If we want to create such a model, we start by counting the occurrences of a sequence of a fixed length in the existing linguistic resources. Therefore, whole texts are analysed and single occurrences (1 gram) twos (2 grams) and triples (3 grams) are counted. We can also obtain a 4-gram model, but here huge sets of data are needed, which makes it challenging for the Polish language to implement.
Then you convert the number of occurrences into probability by normalizing. In this way, we obtain the prediction of the next element based on the sequences so far. The more text we analyse, the higher the quality of the model will be. This data is used in natural language processing (NLP) applications. However, there are methods that allow n-gram models to be improved by smoothing the collected statistics. This model is primarily characterized by scalability. We can choose a schema without a lot of data, but then it will be less predictive. The n-gram model for the Polish language can be found here.
The use of the n-gram model at the inference stage allows to correct the output of the neural network (transcription of the deepspeech 2 model) in accordance with the rules contained in the n-gram model.
Operation on a limited set of commands
Unfortunately, the models built cannot be learned well enough due to the small amount of data in a language we work in – Polish. In our case, we can operate in a limited set of commands. This means that a specific number of voice commands will be recognized. Our task was to match the appropriate command from the set with what the model provides us. It is important here to define the highest similarity between the command and what the model returned to us.
For this task, we used a metric called Levenshtein distance, which indicates the similarity between the transcript and a given command. It consists of counting items or letters that do not match. For example, the Levenshtein distance between the terms:
- Gravity
- Gravity
Is zero. These words are identical, so no action is required here.
On the other hand, the Levenshtein distance between the words:
- Long
- Pork
Is 3, because it takes at least 3 actions: replace L with P, replace n with r, and replace g with k.
Where there are fewest substitutions, we have the greatest probability that the commands are the same.
Summary
The purpose of voice recognition systems is to ensure ease of communication between the device and the human being. Speech recognition technology is already a part of our daily lives. For now, it is limited to relatively simple commands. Building such a system based on data in the Polish language is a difficult task due to the small amount of data. Taking into account the current trends in the use of smart devices and technical possibilities, it is worth exploring the potential of these systems.
Inero Software provides knowledge and expertise on how to successfully use cutting edge technologies and data to shape corporate digital products of the future.
In the blog post section you will find other articles about IT systems and more!
Consulted by: Tymoteusz Cejrowski, Software Developer.