


Planning tasks in Java
 In the last post by my teammate we presented how to manage back-end long-running asynchronous tasks from the client side. This approach is used especially in handling the appropriate flow of processes and the timely implementation of specific IT system services that require significant amount of computations. From the backend implementation perspective, one of the libraries that enable task scheduling and easy integration with Java Spring applications is Quartz. In the following sections of the article, the general problem of running background tasks and a use case presenting an example solution will be described.
In the last post by my teammate we presented how to manage back-end long-running asynchronous tasks from the client side. This approach is used especially in handling the appropriate flow of processes and the timely implementation of specific IT system services that require significant amount of computations. From the backend implementation perspective, one of the libraries that enable task scheduling and easy integration with Java Spring applications is Quartz. In the following sections of the article, the general problem of running background tasks and a use case presenting an example solution will be described.

Description of the problem
In some cases, the specification of an IT system requires long-running tasks to be performed in background. Compared to synchronous jobs where we wait for output, background jobs allow us to move on to the next job before our primary task is finished. This can be achieved by executing independent tasks in separate threads, which inform the main thread of the application when particular background job is completed. In this case, one thread can be a code block or a method that is a separate unit of work.
The advantages of asynchronous job scheduling tasks include:
- application performance,
- responsiveness and scalability,
- the ability to update the progress or parameters of the task,
- productive planning of service delivery,
- the ability to perform the following tasks without freezing the application state.
However, when running background, it is important to remember to skillfully choose between asynchronous and synchronous programming. If You are dealing with simple, short-lived calculations, it is not a good idea to use background tasks. For instance, too many asynchronous calls between main thread and background can make your code less readable, may cause slow application performance or even lead to thread lock and interrupt application lifecycle.
Check out how we deal with such problems in our team.
Use case, solution
In this post, as an example of using asynchronous programming, we will use a big data download service. Let us assume that a potential user of our website would like to transfer a certain number of files using logic provided by our backend application. As it is presented in the diagram below, the user interface allows to execute task that starts to transfer the file via request made to application server. Since we expect that this task will be a long running one, our goal is to schedule this job to be performed in background thread. Let’s have a look at details:
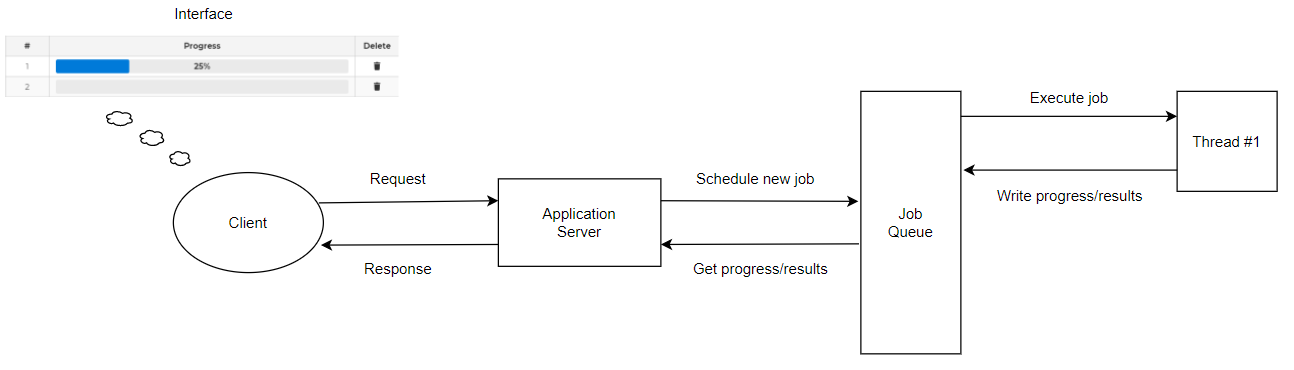
In applications based on Spring, the aforementioned Quartz library is the perfect choice. It allows you to schedule tasks depending on our needs.
Let’s make the following assumptions:
- the user can order to download several files at a time,
- in this case, the tasks will be performed sequentially,
- the user can (interrupt) tasks,
- user is provided with information about tasks, such as id or user data, in the database.
Note that with the use of Quartz, you can execute threads simultaneously, but for the purpose of this post will used the task queue. The key interfaces used in this API are Scheduler, Job, JobDetail, JobDataMap, Trigger.
Initially, you need to create a Scheduler instance as the main interaction component. This can be done by injection into a class or by using the lines of code below.
SchedulerFactory schedulerFactory = new StdSchedulerFactory(); Scheduler scheduler = schedulerFactory.getScheduler();
The next step is to define an example class, in this case FileDownloadJob, extended by the QuartzJobBean class, which implements the Job interface. The main method executeInternal(), will be called by one of the Scheduler threads after the Trigger is fired. Inside it, the target action of a given task should be performed.
public class FileDownloadJob extends QuartzJobBean {
@Override
protected void executeInternal(JobExecutionContext jobExecutionContext) throws JobExecutionExceptions{
// target code of performed operations
}
}
The job scheduling process consists of assigning a unique key “JobKey”, preparing a JobDataMap and building a JobDetail instance. Assuming the “task” object is one of the records in the task database repository, the operations in question can be performed with the following lines of code.
JobKey jobKey = JobKey.jobKey((task.getId());
JobDataMap jobData = new JobDataMap();
jobData.putAll(new HashMap<>() {{
put("email", user.getEmail());
put("name", user.getName());
put("progress", task.getProgress());
}});
JobDetail jobDetail = newJob().ofType(FileDownloadJob.class)
.withIdentity(jobKey)
.setJobData(jobData)
.build();
If we have all the details, we can fire the trigger and plan our task.
Trigger trigger = newTrigger()
.startNow()
.build();
scheduler.scheduleJob(jobDetail, trigger);
Returning to the assumptions of the solution, consider the possibility of deleting tasks. In the Quartz library it is possible to additionally implement the InterruptableJob interface in our job class.
public class FileDownloadJob extends QuartzJobBean implements InterruptableJob
It implements the interrupt() method where we can stop the job.
@Override
public void interrupt() {
_interrupted = true;
}
Assuming that the operations performed inside the job are carried out in a loop, we can check the given _interrupted field, and for example if it is equal to True, terminate the job.
if (_interrupted) {
break;
}
Of course, this is just an example of a job interruption. It is fully dependent on the operations performed within the method of execution. From the Scheduler side, the method shown below allows us to call the interrupt() method inside our FileDownloadJob class.
scheduler.interrupt(jobKey);
Another functionality is the sequential execution of tasks. This can be implemented in various ways, such as JobListener or smart use of JobDataMap. In our use case, we choose the second option, due to the possibility of further expansion, i.e. updating progress, stopping and resuming tasks.
Let’s add another field in our map and fill it with the id of the next job, assuming that all information about the tasks is stored in the database.
jobDataMap.put("nextJob", nextTask.getId());
Thanks to this, when we finish the operation of the first job, we can check if there is a unique key in the “nextJob” field of JobDataMap. If so, we move on to the next task. If we would like to add the functionality of changing the order of task execution, we could define another “previousTask” field storing the id of the previous task. Based on this, we could define appropriate methods to modify the queue position. In addition, in our map we can store the previously mentioned information about the current data download process and update it via REST endpoints in the client interface.
Java Scheduling – Summary
Asynchronous programming is an essential element in delivering some IT system services. However, it should be remembered that the use of background tasks should be carefully selected for the problem in order to avoid unnecessary conflicts or system overload. If you are using Java, the Quartz library is a good choice that allows you to easily integrate the planning process with our application. Try this!