

Running large language models (LLMs) on your own hardware has become increasingly feasible thanks to lightweight LLMs—models with relatively small parameter counts that deliver strong performance without requiring server-grade GPUs. In this post, we’ll explore several top open-source lightweight LLMs and how to run them on a local Windows PC—whether CPU-only or with a limited GPU—for document processing tasks. We also include a benchmark comparing the models in terms of accuracy and inference speed, helping you choose the right model for your local environment and use case.
What Are Lightweight LLMs (and Why Run Them Locally)?
“Lightweight” LLMs are models typically in the range of ~1–8 billion parameters – far smaller than GPT-3 class models – often optimized to run on a single GPU or even CPU. They are usually released as open models with freely available weights. These models trade some raw power for efficiency, but recent research and clever engineering (better data, distilled training, efficient attention mechanisms, etc.) have dramatically improved their capabilities. Many can now match or beat much larger models on specific benchmarks.
Local deployment of such models is valuable for several reasons:
- Privacy & Security: All data stays on your machine, which is crucial for confidential documents like insurance contracts. You’re not sending sensitive text to a third-party API.
- Cost Savings: Once downloaded, local models run for free – no API usage fees or cloud compute bills. This can make a big difference if you process large volumes of documents regularly.
- Latency & Offline Access: Local inference eliminates network latency. Responses can be near-instant on a GPU, and you can operate entirely offline. This is useful for on-site workflows or when internet access is restricted.
- Customization: With local models you have full control – you can adjust parameters, prompts, or fine-tune models to better fit your domain (e.g. insurance data) without vendor limits.
In short, lightweight LLMs put AI capabilities directly in your hands, on hardware you own. Next, we’ll compare some of the leading open models that are well-suited for local document processing.
Comparing Top Lightweight LLMs
Lightweight open-source large language models (LLMs) are becoming a practical choice for organizations looking to run AI workloads locally. They offer a strong balance between performance, speed, and resource requirements—making them ideal for document summarization, extraction, and classification without relying on cloud infrastructure.
We’ll focus on the following open-source models (each with downloadable checkpoints) that have a good reputation for quality relative to their size:
- Llama 3.1 – 8B parameters (Meta AI)
- StableLM Zephyr – 3B parameters (Stability AI)
- Llama 3.2 – 1B/3B parameters (Meta AI)
- Mistral – 7B parameters (Mistral AI)
- Gemma 3 – 1B and 4B variants (Google DeepMind)
- DeepSeek R1 – 1.5B and 7B variants (DeepSeek AI)
- Phi-4 Mini – 3.8B parameters (Microsoft)
- TinyLlama – 1.1B parameters (community project)
- These models range from very small (under 1 GB on disk) to mid-sized (~5 GB). All can be run in inference mode on a 16 GB GPU (often even in half-precision or 4-bit quantized form) and many are workable on CPU with enough RAM and patience. Table 1 summarizes their characteristics:
| Model | Size on Disk (quantized) | Max Context | Licence |
|---|---|---|---|
| Llama 3.1 (8B) | 4.9GB | 128k tokens | Open-source |
| StableLM Zephyr (3B) | 1.6GB | 4k tokens | Only non-commercial use |
| Llama 3.2 (3B) | 2.0GB | 128k tokens | Open-source |
| Mistral (7B) | 4.1GB | 32k tokens | Open-source (Apache 2.0) |
| Gemma 3 (4B) | 3.3GB | 128k tokens | Open-source |
| Gemma 3 (1B) | 0.8GB | 32k tokens | Open-source |
| DeepSeek R1 (7B) | 4.7GB | 128k tokens | Open-source (MIT licence) |
| DeepSeek R1 (1.5B) | 1.1GB | 128k tokens | Open-source (MIT licence) |
| Phi-4 Mini (3.8B) | 2.5GB | 128k tokens | Open-source |
| TinyLlama (1.1B) | 0.6GB | 2k tokens | Open-source |
Table 1: Lightweight LLMs for local use – model sizes and maximum context window.
Notes: “Max Context” is the maximum sequence length (tokens) the model can process in one go.
Next, let’s look at each model’s pros and cons, especially in the context of document tasks:
- Llama 3.1 (8B): Powerful general-purpose model; moderate size and strong multilingual capabilities. Heavy for CPU-only systems; requires chunking for long documents.
- StableLM Zephyr (3B): Ultra-lightweight, good for basic QA/extraction. Limited by small parameter count and commercial license restrictions.
- Llama 3.2 (3B): Excellent summarization and retrieval; long context support (128k tokens). Smaller size affects complex reasoning accuracy.
- Mistral (7B): Best overall performer for its size; highly efficient inference. Ideal for detailed summarization tasks.
- Gemma 3 (4B/1B): Offers multimodal capabilities and extensive multilingual support. The 4B model balances capability and speed; the 1B model best suited for simple tasks.
- DeepSeek R1 (7B/1.5B): Balanced efficiency and comprehension for general NLP tasks; limited complex reasoning compared to Mistral.
- Phi-4 Mini (3.8B): Exceptional reasoning, math, and logical capabilities; perfect for analytical document processing. English-focused.
- TinyLlama (1.1B): Extremely lightweight; suitable for basic text extraction/classification tasks. Limited contextual understanding.
The models reviewed above cover a wide range of sizes and capabilities. Larger variants like Llama 3.1 and Mistral perform well on complex summarization and multilingual tasks but are less suited for CPU-only setups. Mid-sized models such as Llama 3.2 and Gemma 3 (4B) handle long inputs efficiently with reasonable performance. Smaller models, including TinyLlama and StableLM Zephyr, are lightweight and fast, making them practical for basic extraction or classification tasks.
Models Benchmarking: Document Extraction and Summarization
Here we outline a simple model benchmarking plan covering two common document-processing tasks:
- Information Extraction: We evaluated how well each model can extract specific fields from a policy or certificate. Specifically, we prompted each model to find the policy number, insured name, VAT ID, address and insurance period in the document text and return the structured output – clean JSON response with all the needed values.
- Summarization: Each model generated a concise summary of an insurance policy, covering key points such as coverage, exclusions, and conditions.We rated the summaries on clarity, correctness, factual accuracy and readability and penalized heavily fabricating information.
We used 11 documents and ran all tests using Ollama (you can read about running model with Ollama here). The benchmarks were performed on a PC equipped with an NVIDIA GeForce RTX 2060 and 6 GB VRAM. To ensure consistent results, each model was run with temperature set to 0 for the extraction task (to produce deterministic outputs), and with a fixed temperature of 0.7 for summarization. For the extraction task, we also used structured outputs:
{
"model": "deepseek-r1:7b",
"prompt": "You are an assistant that extracts insurance-related information from a given input text. You must extract and return only the following fields: - policy_number,- insurance_period,- insured (company or person name),- nip (tax identification number),- address (of the insured). Return the output as a **clean JSON object** — not as a string, not inside quotes, and without any commentary. If a field is missing, use 'Not found'. Document text: ",
"stream": false,
"format": {
"type": "object",
"properties": {
"policy_number": {
"type": "string"
},
"insurance_period_start": {
"type": "string"
},
"insurance_period_end": {
"type": "string"
},
"insured": {
"type": "string"
},
"insured_nip": {
"type": "string"
},
"insured_address": {
"type": "string"
}
},
"required": [
"policy_number",
"insurance_period_start",
"insurance_period_end",
"insured",
"insured_nip",
"insured_address"
]
}
}

Examples of insurance certifacates.
The table below presents the benchmark results. Extraction accuracy refers to the number of documents (out of 11) where the model successfully extracted all key fields. Token/sec indicates the model’s inference speed — how quickly it generates responses.
| Model | Summarization | Extraction Accuracy | Tokens/sec |
|---|---|---|---|
| Llama 3.1 (8B) | High-quality, no hallucinations | 10/11 | 13.49 |
| StableLM 3B | Average quality, typos/hallucinations | 4/11 | 56.51 |
| Llama 3.2 (3B) | Concise yet comprehensive summary, no hallucinations | 8/11 | 49.49 |
| Mistral 7B | Extensive summary, factually correct | 8/11 | 29.01 |
| Gemma 3 4B | Concise yet comprehensive summary, no hallucinations | 10/11 | 13.37 |
| Gemma 3 1B | Concise yet comprehensive summary, no hallucinations | 4/11 | 73.46 |
| DeepSeek 7B | Concise yet comprehensive summary, no hallucinations | 6/11 | 16.39 |
| DeepSeek 1.5B | Very poor, frequent hallucinations/errors | 0/11 | 66.45 |
| Phi-4 Mini 3.8B | Very concise summaries, factually correct | 9/11 | 39.31 |
| TinyLlama 1.1B | Poor quality, severe hallucinations | 2/11 | 107.34 |
Table 2: Benchmarking results.
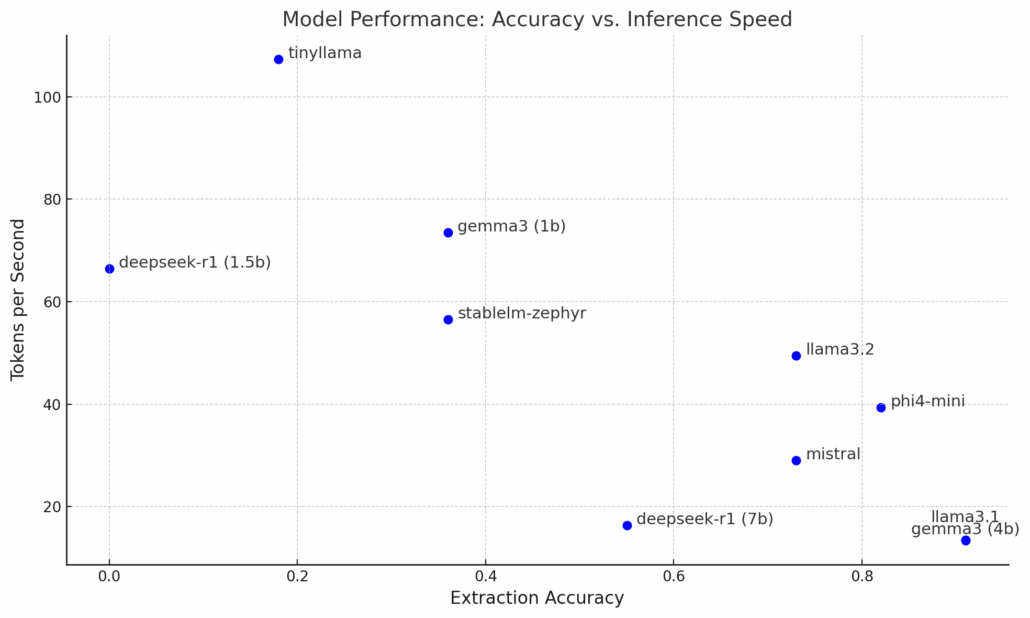
This scatterplot visualizes the trade-off between extraction accuracy and inference speed (measured in tokens per second)
The benchmarking results reveal significant variations among the tested models.
- Bottom-right models – Llama 3.1 (8B), Gemma 3 (4B), and Phi-4 Mini (3.8B) – excel in summarization quality and extraction accuracy, consistently providing concise and accurate outputs. Phi-4 Mini seems to offer a good trade-off between speed and accuracy.
- Mistral 7B, DeepSeek 7B, Llama 3.2 generate detailed and informative summaries, though their extraction performance is more moderate.
- On the other hand, smaller models (on the top-left side of the chart) like StableLM Zephyr (3B), Gemma 3 (1B) and TinyLlama (1.1B) show significantly weaker extraction accuracy and are prone to frequent hallucinations. However, they benefit from faster inference times. Their limited context windows (e.g., 4k tokens) may contribute to these shortcomings. Overall, they may be suitable for only very basic tasks.
Choosing the Right Model for Your Needs
When selecting a language model for document extraction or summarization, it’s all about balancing accuracy, speed, and hardware constraints. Below is a quick breakdown to help you pick the best fit—whether you need high precision, fast inference, or something lightweight for basic tasks.
- High Accuracy & Reasonable Speed: Choose Phi-4 Mini (3.8B), Gemma 3 (4B), or Llama 3.1 (8B) for robust extraction and summarization accuracy.
- Fast Inference & Moderate Accuracy: Opt for Llama 3.2 (3B) or StableLM Zephyr (3B) for simpler tasks on limited hardware.
- Balanced Performance (Accuracy-Speed Tradeoff): Mistral (7B) provides strong general-purpose capability suitable for detailed document summarization tasks.
- Low Resource Environments (Basic Tasks): Consider TinyLlama (1.1B) for quick extraction or classification on minimal hardware if accuracy isn’t critical.
Conclusion
Lightweight LLMs are increasingly viable solutions for local deployment, particularly in document-intensive industries such as insurance. Models such as Phi-4 Mini, Gemma 3 (4B), and Mistral 7B provide strong performance in summarization, extraction, and classification tasks. Carefully balancing model size, inference speed, and accuracy ensures optimal outcomes, empowering organizations with affordable, private, and responsive AI solutions directly on owned hardware.