

Wraz z rosnącym zapotrzebowaniem na aplikacje działające w czasie rzeczywistym, uruchamianie modeli głębokiego uczenia w przeglądarce staje się coraz bardziej dostępne i wydajne. W tym artykule pokażemy, jak zaimplementować wykrywanie obiektów bezpośrednio w przeglądarce, wykorzystując YOLO (You Only Look Once) oraz TensorFlow.js. Skoncentrujemy się na zastosowaniu wytrenowanego przez nas niestandardowego modelu YOLOv8 do wykrywania ludzkich twarzy. Na końcu tego przewodnika dowiesz się, jak skonfigurować i uruchomić model YOLO do wykrywania twarzy za pomocą TensorFlow.js, przetworzyć wyniki i zoptymalizować wydajność – wszystko to bez potrzeby korzystania z serwera czy przetwarzania po stronie backendu.
Dlaczego warto korzystać z sieci neuronowych w przeglądarce?
Uruchamianie sieci neuronowych w przeglądarce ma wiele zalet. Najważniejsze z nich to:
- Niskie opóźnienia: Wszystko odbywa się po stronie klienta, co eliminuje opóźnienia wynikające z przesyłania danych na serwer i oczekiwania na odpowiedź.
- Większa prywatność: Wrażliwe dane pozostają na urządzeniu użytkownika, co minimalizuje ryzyko ich naruszenia lub ujawnienia.
- Możliwość użycia offline: Użytkownicy mogą korzystać z funkcji uczenia maszynowego nawet bez stałego połączenia z internetem.
- Kompatybilność między platformami: Aplikacja działa na każdym urządzeniu z przeglądarką – niezależnie czy to komputer, tablet, czy smartfon.
Wybór i przygotowanie sieci neuronowej
Przy wyborze sieci neuronowej do implementacji w przeglądarce warto uwzględnić takie czynniki jak rozmiar modelu, szybkość działania, zużycie pamięci oraz kompatybilność z technologiami przeglądarkowymi, np. WebGL. Dla optymalnej wydajności na urządzeniach o ograniczonych zasobach zaleca się stosowanie modeli o rozmiarze poniżej 30 MB. Do odpowiednich modeli należą MobileNetV2, SqueezeNet, EfficientNet oraz wybrane warianty YOLO. My zdecydowaliśmy się na wytrenowany przez nas model YOLOv8 do wykrywania ludzkich twarzy na obrazach.
Jeśli Twój model przekracza zalecany rozmiar, warto rozważyć techniki optymalizacji, takie jak kwantyzacja (quantization) i przycinanie (pruning). Kwantyzacja zmniejsza precyzję wag modelu, zazwyczaj konwertując wartości zmiennoprzecinkowe 32-bitowe na liczby zmiennoprzecinkowe 16-bitowe lub całkowite 8-bitowe. Przycinanie usuwa zbędne połączenia w sieci neuronowej. Obie metody zmniejszają rozmiar modelu i redukują złożoność obliczeniową, co poprawia szybkość inferencji – szczególnie na urządzeniach takich jak smartfony – choć mogą one nieznacznie wpłynąć na dokładność.
Optymalizacja YOLOv8 do wykrywania twarzy: wyniki naszego niestandardowego modelu
Nasz model YOLOv8 został wytrenowany na niestandardowym zbiorze danych w celu automatycznego sprawdzania, czy załącznik zawiera wyraźne zdjęcie ludzkiej twarzy, skierowanej na wprost i niezasłoniętej, np. przez maskę. Taka funkcjonalność jest szczególnie przydatna w systemach obiegu dokumentów, gdzie weryfikacja tożsamości wymaga widoczności twarzy. Zbiór danych składał się z 1500 obrazów, z czego 1200 wykorzystano do treningu, a 300 do walidacji. Dataset zawierał zdjęcia twarzy fotografowanych z różnych kątów, twarzy częściowo zasłoniętych oraz zdjęcia innych obiektów. Dzięki treningowi model nauczył się skutecznie wykrywać twarze spełniające wymagane kryteria. Poniższe przykłady ilustrują, jak model działa w praktyce. Dwie twarze po lewej stronie zostały poprawnie wykryte, podczas gdy dwie po prawej nie zostały rozpoznane, ponieważ były częściowo zasłonięte:
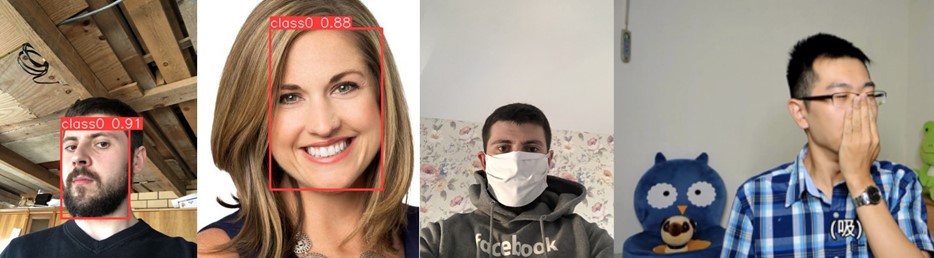
(source of images: https://www.kaggle.com/datasets/ashwingupta3012/human-faces, https://www.kaggle.com/datasets/andrewmvd/face-mask-detection)
Wyniki wnioskowania na czterech przykładach – dwie twarze po lewej stronie zostały poprawnie wykryte, natomiast dwie po prawej nie, ponieważ były częściowo zasłonięte.
Jako bazowy model dla naszego projektu wybraliśmy YOLOv8s (small), co dało model o rozmiarze 44 MB, osiągający 99,9% precyzji (ang. precision) oraz 99,1% czułości (ang. recall) na naszym niestandardowym zbiorze danych walidacyjnych. W celu optymalizacji przetestowaliśmy również mniejszy model bazowy, YOLOv8n (nano), oraz przeanalizowaliśmy efekty kwantyzacji. Trening z modelem YOLOv8n dał model o rozmiarze zaledwie 12 MB, przy niemal identycznych wynikach – 99,7% precyzji i 99,1% czułości. Następnie przeprowadziliśmy kwantyzację obu modeli, a ich rozmiary oraz dokładność po kwantyzacji zostały zaprezentowane w poniższej tabeli:
| Model bazowy
| Model kwantyzowany 16-bitowy
| ||||
Rozmiar | Precyzja | Recall | Rozmiar | Precyzja | Recall | |
YOLOv8 small | 44 MB | 0.999 | 0.991 | 22 MB | 0.997 | 0.991 |
YOLOv8 nano | 12 MB | 0.997 | 0.991 | 6 MB | 0.989 | 0.991 |
Uwaga: Czułość mierzy, ile rzeczywistych pozytywnych próbek zostało poprawnie zidentyfikowanych (tutaj: ile twarzy zostało poprawnie wykrytych), natomiast precyzja wskazuje, ile próbek zidentyfikowanych przez model jako pozytywne było faktycznie pozytywnych (tutaj: ile obiektów wykrytych przez model to faktycznie ludzkie twarze). W idealnym przypadku oba wskaźniki wynoszą 1.
W naszym przykładzie, zastosowanie mniejszego modelu bazowego wraz z kwantyzacją zmniejszyło dokładność o mniej niż 1%, jednocześnie redukując rozmiar modelu z 44 MB do zaledwie 6 MB.
Poniżej przedstawiamy kilka przykładowych zdjęć, które pokazują, jak działają dwa modele: YOLOv8s i YOLOv8n z kwantyzacją.

Wyniki inferencji z modelem YOLOv8s, bez kwantyzacji (o rozmiarze 44 MB):
(source of images: https://www.kaggle.com/datasets/ashwingupta3012/human-faces).

Wyniki inferencji z modelem YOLOv8n po kwantyzacji 16-bitowej (o rozmiarze 6 MB). Różnica w poziomie ufności jest minimalna, natomiast położenie wykrytych obiektów pozostało takie samo.
Przetestowaliśmy wydajność dwóch modeli — YOLOv8s (44 MB) i YOLOv8n po kwantyzacji 16-bitowej (6 MB) — na trzech różnych procesorach. Mniejszy model, YOLOv8n, konsekwentnie przewyższał swój większy odpowiednik pod względem czasu wczytania modelu oraz szybkości pojedynczej inferencji. Szczegółowe dane dotyczące wydajności zostały podsumowane w tabeli poniżej.
| Ładowanie modelu | Pojedyncze wnioskowanie | ||||
CPU 1 | CPU 2 | CPU 3 | CPU 1 | CPU 2 | CPU 3 | |
YOLOv8 small | 1050 ms | 3700 ms | 4200 ms | 21 ms | 117.5 ms | 196.5 ms |
YOLOv8 nano 16-bit | 980 ms | 3200 ms | 3700 ms | 16 ms | 112.5 ms | 189 ms |
Przyspieszenie | 6.7 % | 13.5 % | 11.9 % | 23.8 % | 4.2 % | 3.8 % |
Oprócz czasu wczytania modelu i inferencji, istotnym czynnikiem do rozważenia jest również czas pobrania modelu, który nie został uwzględniony w tabeli. Czas ten jest bezpośrednio proporcjonalny do rozmiaru modelu i w znacznym stopniu zależy od prędkości połączenia internetowego użytkownika.
Praktyczna implementacja krok po kroku
Aby wdrożyć model uczenia maszynowego w przeglądarce, skorzystamy z TensorFlow.js — popularnej biblioteki, która umożliwia uruchamianie wytrenowanych modeli lub całkowite trenowanie nowych modeli bezpośrednio w przeglądarce. W tym przewodniku skupimy się na wdrożeniu wytrenowanego modelu YOLOv8 do wykrywania twarzy. Poniżej znajdziesz instrukcję, jak krok po kroku skonfigurować środowisko i uruchomić model z TensorFlow.js.
1. Instalacja TensorFlow.js
Najłatwiejszą metodą instalacji Tensorflow.js jest użycie npm:
npm install @tensorflow/tfjs
2. Wczytanie modelu
Ponieważ używamy biblioteki TensorFlow.js, musisz przekonwertować swój model na format TensorFlow.js (Tf.js). W przypadku modeli YOLO, twórcy Ultralytics udostępnili łatwy sposób na dokonanie tego za pomocą prostego polecenia:
yolo export model=path/to/best.pt format=tfjs
Po konwersji Twój model zostanie zapisany jako pliki binarne wraz z plikiem JSON o nazwie model.json. Wówczas możesz wczytać model korzystając z funkcji tf.loadGraphModel(). Poniżej znajdziesz przykład implementacji. Zwróć uwagę na dodatkowy etap „rozgrzewki” modelu, poprzez wykonanie jednokrotnej inferencji na losowych danych wejściowych. Ten krok poprawi wydajność modelu przy kolejnej inferencji.
export async function loadModel(modelPath) {
try {
// Load the model using a URL
const model = await tf.loadGraphModel(`${modelPath}/model.json`);
// Warm up the model
const dummyInput = tf.ones(model.inputs[0].shape);
await model.execute(dummyInput);
return model;
} catch (error) {
throw new Error(`Failed to load model: ${error.message}`);
}
}
3. Przygotowanie danych wejściowych
Przed uruchomieniem modelu musimy odpowiednio przygotować obraz wejściowy. Modele YOLO oczekują obrazów o określonym rozmiarze, takim samym jaki został użyty podczas treningu sieci. Zamiast jednak zmieniać rozmiar obrazu (np. funkcją resize()), zalecamy bardziej zaawansowaną metodę przetwarzania obrazu, która zachowuje proporcje i stosuje wypełnienie (letterbox padding). Takie podejście jest zgodne z przetwarzaniem stosowanym przez Ultralytics podczas trenowania modelu YOLO i zapewni najlepszą skuteczność.
Poniższa funkcja skaluje obraz tak, aby największy jego wymiar zgadzał się z tym oczekiwanym przez model, dodaje wypełnienie aby dopasować drugi wymiar obrazu (jeżeli trzeba) i normalizuje obraz wejściowy:
function preprocessImage(base64Image, imgSize) {
const image = new Image();
image.src = base64Image;
const canvas = document.createElement('canvas');
canvas.width = image.width;
canvas.height = image.height;
const ctx = canvas.getContext('2d');
ctx.drawImage(image, 0, 0, image.width, image.height);
// Convert canvas image to a tensor
let imgTensor = tf.browser.fromPixels(canvas);
// Determine rescale factor
const xFactor = image.width / imgSize;
const yFactor = image.height / imgSize;
const factor = Math.max(xFactor, yFactor);
const newWidth = Math.round(image.width / factor);
const newHeight = Math.round(image.height / factor);
// Resize to expected input shape
imgTensor = tf.image.resizeBilinear(imgTensor, [newHeight, newWidth]);
// Add padding
const xPad = (imgSize - newWidth) / 2;
const yPad = (imgSize - newHeight) / 2;
const top = Math.floor(yPad);
const bottom = Math.ceil(yPad);
const left = Math.floor(xPad);
const right = Math.ceil(xPad);
imgTensor = tf.pad(imgTensor, [[top, bottom], [left, right], [0, 0]], 114);
// Normalize pixel values
imgTensor = imgTensor.div(255.0).expandDims(0); // Add batch dimension
return { imgTensor, left, top, factor };
}
4. Uruchom inferencję modelu
Po załadowaniu modelu i przetworzeniu danych wejściowych, wykonanie inferencji odbywa się za pomocą tej linii kodu:
const prediction = await model.execute(inputTensor);
5. Przetwarzanie wyników modelu
Wynik sieci YOLO to tensor, który należy odpowiednio zinterpretować. Poniżej znajdują się kroki w naszej funkcji postprocessInferenceResults(), które pozwalają na wyodrębnienie współrzędnych wszystkich wykrytych obiektów:
const results = prediction.transpose([0, 2, 1]);
const numClass = 1; // Only one class in our case
const boxes = tf.tidy(() => {
const w = results.slice([0, 0, 2], [-1, -1, 1]); // Get width
const h = results.slice([0, 0, 3], [-1, -1, 1]); // Get height
const x1 = tf.sub(results.slice([0, 0, 0], [-1, -1, 1]), tf.div(w, 2)); // Get x1
const y1 = tf.sub(results.slice([0, 0, 1], [-1, -1, 1]), tf.div(h, 2)); // Get y1
return tf.concat([y1, x1, y1.add(h), x1.add(w)], 2).squeeze();
});
Aby wyodrębnić klasy i poziomy ufności dla każdego obiektu:
const numClass = labels.length;
const [scores, classes] = tf.tidy(() => {
const rawData = results.slice([0, 0, 4], [-1, -1, numClass]).squeeze(0);
return [rawData.max(1), rawData.argMax(1)];
});
Następnie należy pozbyć się wyników z poziomem ufności poniżej ustalonego progu (u nas był to 0.4):
const array = await scores.array();
const highConfidenceIndices = array.reduce((acc, value, index) => {
if (value > 0.4) acc.push(index);
return acc;
}, []);
const highConfidenceBoxes = boxes.gather(highConfidenceIndices);
const highConfidenceScores = scores.gather(highConfidenceIndices);
const highConfidenceClasses = classes.gather(highConfidenceIndices);
Na koniec zastosuj Non-Max Suppression (NMS), aby odfiltrować duplikaty, tzn. wykryte obiekty, które się na siebie nakładają:
const nms = await tf.image.nonMaxSuppressionAsync(highConfidenceBoxes, highConfidenceScores, 40, 0.45, 0.4); // NMS to filter boxes
const boxesData = highConfidenceBoxes.gather(nms, 0); // Indexing boxes by NMS index
const scoresData = highConfidenceScores.gather(nms, 0).dataSync(); // Indexing scores by
const classesData = highConfidenceClasses.gather(nms, 0).dataSync(); // Indexing classes by NMS index
Ostatnim krokiem jest przeskalowanie współrzędnych, aby dopasować je do kształtu oryginalnego obrazu:
// Precompute the margins and factors outside the stack
const yMarginTensor = tf.scalar(yMargin);
const xMarginTensor = tf.scalar(xMargin);
const resizeFactorTensor = tf.scalar(resizeFactor);
// Slice the boxesData and apply transformations in one step
const [yCoordinates, xCoordinates, height, width] =
['0', '1', '2', '3'].map((index) =>
boxesData.slice([0, parseInt(index)], [-1, 1]).sub(index % 2 === 0 ? yMarginTensor : xMarginTensor).mul(resizeFactorTensor)
);
// Stack the tensors without converting to arrays (unless needed)
const bbox = tf.stack([yCoordinates, xCoordinates, height, width], 1);
// Convert to an array only if absolutely necessary
const bboxArray = bbox.arraySync();
Na końcu możemy zdefiniować funkcję runInference(), która zawiera cały opisany powyżej proces wykrywania obiektów. Ta funkcja zawiera przygotowanie obrazu, uruchomienie inferencji modelu oraz przetworzenie wyników. Oto jak wygląda:
export async function runInference(model, labels, image, confidenceThreshold = 0.4) {
try {
// Preprocess the image
const imgSize = model.inputs[0].shape[1];
const { imgTensor: inputTensor, left: xMargin, top: yMargin, factor: resizeFactor } = preprocessImage(image, imgSize);
// Run inference
const prediction = await model.execute(inputTensor);
// Post-process the model output
const [boxes, scores, classes] = await postprocessInferenceResults(prediction, labels, xMargin, yMargin, resizeFactor, confidenceThreshold);
return [boxes, scores, classes];
} catch (error) {
throw new Error(`Inference failed: ${error.message}`);
}
}
6. Wizualizacja wyników
Na samym końcu, gdy mamy już gotowe wyniki detekcji, możemy narysować wykryte obiekty na obrazie:
function drawBoxesOnCanvas(ctx, boxes, classes, scores, colors) {
boxes.forEach((box, i) => {
const [x1, y1, x2, y2] = box;
ctx.strokeStyle = colors[classes[i]];
ctx.lineWidth = 2;
ctx.strokeRect(x1, y1, x2 - x1, y2 - y1);
ctx.fillStyle = colors[classes[i]];
ctx.fillText(`${labels[classes[i]]} (${Math.round(scores[i] * 100)}%)`, x1, y1);
});
}
Podsumowując, uruchamianie modelu YOLO do wykrywania obiektów bezpośrednio w przeglądarce przy użyciu TensorFlow.js otwiera nowe możliwości dla aplikacji real-time. W tym wpisie przedstawiliśmy wszystkie kroki, od konfiguracji TensorFlow.js, przez ładowanie modeli, przetwarzanie obrazów, uruchamianie wnioskowania, aż po wizualizację wyników, wraz ze wskazówkami jak zrobić to efektywnie. W miarę dalszego zgłębiania tej ciekawej technologii, warto eksperymentować z różnymi modelami, technikami optymalizacji oraz przypadkami użycia, aby w pełni wykorzystać potencjał uczenia maszynowego w aplikacjach internetowych.