

Modele Retrieval-Augmented Generation (RAG) zmieniają sposób, w jaki inteligentni asystenci przetwarzają informacje, umożliwiając bardziej precyzyjne i kontekstowe odpowiedzi na zapytania użytkowników. W przeciwieństwie do tradycyjnych dużych modeli językowych (LLMs), systemy RAG łączą dwa kluczowe elementy: mechanizm wyszukiwania, który pobiera istotne dokumenty, oraz model generatywny, który tworzy odpowiedzi na podstawie aktualnych danych. W tym artykule przyjrzymy się, jak DeepEval pomaga w systematycznej ocenie skuteczności zarówno wyszukiwania, jak i generowania, zwiększając wiarygodność informacji tworzonych przez AI.
Chociaż wirtualni asystenci wykorzystujący RAG znacząco poprawiają trafność odpowiedzi, ich skuteczna ocena nadal stanowi wyzwanie. Ponieważ modele te opierają się zarówno na mechanizmie wyszukiwania, jak i generowaniu tekstu, niedokładne lub nieefektywne pobieranie dokumentów może prowadzić do błędnych lub mylących odpowiedzi, nawet jeśli sam model językowy (LLM) jest zaawansowany technologicznie.
W tym artykule przedstawimy ten proces na przykładzie naszego autorskiego asystenta AI, zaprojektowanego do udzielania odpowiedzi na złożone pytania dotyczące statystyk gospodarki morskiej. Pokażemy, jak wykorzystanie LLM do inteligentnego wyszukiwania informacji wspiera podejmowanie decyzji opartych na danych.
SeaStat - nasz asystent AI
Świetnym przykładem, który możemy wykorzystać do omówienia tego zagadnienia, jest asystent AI SeaStat, opracowany przez nas w ramach projektu Incone60 Green (https://www.incone60.eu/). Celem tego projektu jest zwiększenie konkurencyjności oraz wspieranie zrównoważonego rozwoju małych portów morskich w regionie południowego Bałtyku.
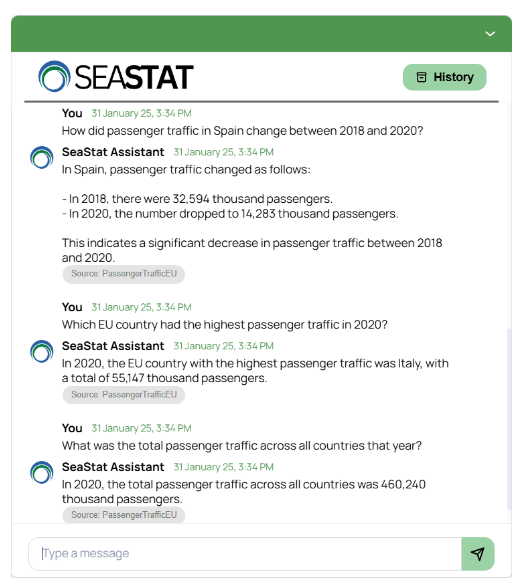
W ramach projektu Incone60 Green opracowaliśmy asystenta AI, który odpowiada na pytania dotyczące danych gospodarki morskiej, zapewniając natychmiastowy dostęp do uporządkowanych informacji. Asystent wykorzystuje podejście Retrieval-Augmented Generation (RAG), dzięki czemu jego odpowiedzi opierają się na ustrukturyzowanej bazie danych obejmującej kluczowe aspekty, takie jak porty morskie, transport morski, stocznie, ruch pasażerski, handel oraz przemysł rybny.
Nasz asystent AI działa w ramach potoku RAG, który integruje trzy kluczowe elementy:
- Ustrukturyzowaną bazę danych gospodarki morskiej, zawierającą globalne i polskie statystyki morskie z lat 2017–2020. Dane pochodzą z publikacji Uniwersytetu Morskiego w Gdyni, które agregują informacje z instytutów rządowych, uczelni oraz przedsiębiorstw portowych. Baza składa się z 50 tabel obejmujących kluczowe aspekty transportu morskiego i będzie rozszerzana o kolejne lata.
- Dynamiczne generowanie zapytań SQL, umożliwiające precyzyjne pobieranie potrzebnych informacji z bazy danych.
- Generatywny model LLM, który formułuje odpowiedzi na podstawie uzyskanych danych.
Budowa takiego asystenta wymaga kilku istotnych decyzji i optymalizacji, w tym:
- Dobór odpowiedniego modelu LLM oraz dostosowanie jego parametrów (np. temperatury).
- Projektowanie skutecznej struktury promptów, zapewniającej jasne i trafne odpowiedzi.
- Zoptymalizowanie mechanizmu wyboru tabel, tak aby asystent konsekwentnie korzystał z najbardziej adekwatnych danych.
Na tym etapie automatyczne testowanie odgrywa kluczową rolę – pozwala mierzyć wydajność systemu, wykrywać jego słabe punkty oraz zapewniać jego stały rozwój.
LLM-as-a-Judge: Automatyzacja ewaluacji modeli RAG
Ocena systemów generujących niedeterministyczne, otwarte odpowiedzi tekstowe stanowi wyzwanie, ponieważ często nie istnieje jedna „poprawna” odpowiedź. Choć ocena przeprowadzana przez ludzi jest precyzyjna, bywa kosztowna i czasochłonna.
LLM-as-a-Judge to metoda, która naśladuje ocenę ludzką, oceniając wyniki systemu na podstawie dostosowanych kryteriów, dopasowanych do konkretnej aplikacji. Jednym z narzędzi wspierających ten proces jest DeepEval – framework testowy, który oferuje zestaw metryk zarówno dla zadań wyszukiwania, jak i generowania tekstu, a także umożliwia tworzenie własnych kryteriów oceny.
Kluczowe metryki oceny:
- G-Eval – uniwersalna metryka oceniająca odpowiedzi LLM na podstawie niestandardowych, zdefiniowanych kryteriów.
- Answer Relevancy – mierzy, jak dobrze odpowiedź modelu odnosi się do zapytania użytkownika.
- Faithfulness – ocenia, na ile odpowiedź jest zgodna z dostarczonym kontekstem, co pomaga ograniczyć halucynacje w systemach RAG.
- ContextualRecallMetric, ContextualPrecisionMetric, ContextualRelevancyMetric – metryki szczególnie przydatne w systemach RAG, oceniające, czy mechanizmy wyszukiwania zwracają wszystkie istotne informacje, jednocześnie eliminując treści nieistotne.
Testowanie modelu RAG za pomocą DeepEval – krok po kroku
Aby zapewnić niezawodność i dokładność naszego modelu Retrieval-Augmented Generation (RAG), stosujemy ustrukturyzowane podejście do ewaluacji. Proces ten obejmuje tworzenie zbioru danych, generowanie odpowiedzi oraz ocenę modelu za pomocą DeepEval, co pozwala na systematyczną analizę skuteczności zarówno komponentu wyszukiwania, jak i generowania.
Przyjrzyjmy się każdemu z tych kroków.
1. Tworzenie Zbioru Danych
Aby skutecznie ocenić wydajność modelu, tworzymy zestaw testowy składający się z:
- Realistycznych pytań użytkowników – obejmujących zarówno proste zapytania faktograficzne, jak i bardziej złożone pytania wieloetapowe, wymagające szczegółowych odpowiedzi na podstawie wielu tabel.
- Oczekiwanych odpowiedzi referencyjnych (ground truth) – pochodzących bezpośrednio z bazy danych, zapewniających wzorzec do oceny poprawności generowanych odpowiedzi.
2. Generowanie Odpowiedzi Modelu
Dla każdego zapytania testowego asystent generuje odpowiedź na podstawie odpowiednich danych pobranych z bazy danych.
3. Ewaluacja za pomocą DeepEval
Szczególnie zależy nam na poprawności faktograficznej naszego asystenta, dlatego do oceny tego aspektu wykorzystujemy metrykę G-Eval.
Musimy zdefiniować G-Eval, opisując kryteria testowe, np.:
correctness_metric = GEval(
name="Correctness",
evaluation_steps=[
"Assess whether the actual output is accurate in terms of facts compared to the expected output.",
"Penalize missing information."
],
evaluation_params=[
LLMTestCaseParams.INPUT,
LLMTestCaseParams.ACTUAL_OUTPUT,
LLMTestCaseParams.EXPECTED_OUTPUT
],
)
Dodatkowo korzystamy z kilku wbudowanych metryk:
contextual_precision = ContextualPrecisionMetric()
contextual_recall = ContextualRecallMetric()
contextual_relevancy = ContextualRelevancyMetric()
answer_relevancy = AnswerRelevancyMetric()
faithfulness = FaithfulnessMetric()
Następnie definiujemy przypadki testowe:
test_case = LLMTestCase(
input=#user prompt,
actual_output=#model output here,
expected_output=#the ground truth response
retrieval_context=#data extracted by retriever, in our case it is data extracted from the database
)
Oto jeden z przypadków testowych, których użyliśmy do oceny naszego asystenta SeaStat:
test_case = LLMTestCase(
input='Compare cargo traffic in Suez Canal and Panama Canal in 2019',
actual_output= 'In 2019, the cargo traffic data for the Suez Canal and Panama Canal was as follows: Suez Canal - 1031 million tons; Panama Canal - 243059 thousand tons. The Suez Canal had significantly higher cargo traffic compared to the Panama Canal in 2019.'
expected_output=' In 2019, the Suez Canal handled 1,031 million tons of cargo, whereas the Panama Canal transported only 243 million tons. This indicates that the Suez Canal carried a substantially higher volume of cargo than the Panama Canal that year.'
retrieval_context=[
{'table': 'Suez_Canal_Cargo_Traffic', 'year': 2019, 'cargo_volume_million_tons': 1031},
{'table': 'Panama_Canal_Cargo_Traffic', 'year': 2019, 'direction': 'Atlantic – Pacific', 'cargo_volume_thousand_tons': 156899}, {'table': 'Panama_Canal_Cargo_Traffic', 'year': 2019, 'direction': 'Pacific – Atlantic', 'cargo_volume_thousand_tons': 86160}
]
)
I przeprowadzamy ewaluację:
assert_test(test_case, [correctness_metric, answer_relevancy, contextual_precision, contextual_recall, contextual_relevancy, faithfulness])
4. Testowanie wyników
DeepEval przypisuje każdej metryce wynik w skali od 0 do 1, wraz z opisowym wyjaśnieniem oceny. Poniżej przedstawiamy wyniki jednego z testów oceniających odpowiedź asystenta SeaStat na zapytanie:
„Porównaj ruch towarowy w Kanale Sueskim i Kanale Panamskim w 2019 roku.”
Interpretacja wyników metryk:
- Contextual Recall (1.0) – Mechanizm wyszukiwania skutecznie pobrał wszystkie kluczowe informacje, zapewniając prawie pełne pokrycie oczekiwanej odpowiedzi.
- Contextual Relevancy (0.95) i Contextual Precision (1.0) – Pobrany kontekst był bardzo trafny, co oznacza, że retriever precyzyjnie dobrał informacje istotne dla zapytania.
- Faithfulness (1.0) – Odpowiedź modelu była w pełni zgodna z dostarczonymi danymi i nie zawierała żadnych halucynacji.
- Answer Relevancy (1.0) – Model dokładnie odpowiedział na pytanie użytkownika, dostarczając kompletną i adekwatną odpowiedź.
- Correctness (0.78) – Wynik był nieco niższy z powodu drobnych rozbieżności liczbowych wynikających z zaokrągleń.
Systematyczna analiza przypadków testowych za pomocą DeepEval dostarcza cennych informacji na temat mocnych stron naszego modelu RAG oraz obszarów wymagających usprawnień. Przyszłe optymalizacje mogą obejmować ulepszenie strategii wyszukiwania, dopracowanie promptów lub dostosowanie parametrów modelu LLM w celu poprawy precyzji faktograficznej.
Test case | Metric | Score | Status | Overall Success Rate |
test_case_0
| Correctness (GEval) | 0.78 (threshold=0.5, evaluation model=gpt-4o, reason=The actual output closely matches the expected output in terms of cargo volumes and comparative conclusion, but the numbers are expressed in different units (thousand tons vs million tons) and slightly differ, which may indicate rounding or conversion discrepancies., error=None) | PASSED | 100% |
Answer Relevancy | 1.0 (threshold=0.5, evaluation model=gpt-4o, reason=The score is 1.00 because the response thoroughly addressed the comparison of cargo traffic in the Suez Canal and the Panama Canal in 2019 with no irrelevant details included. It’s precise and to the point, showcasing a deep understanding of the topic., error=None) | PASSED | ||
Contextual Precision | 1.0 (threshold=0.5, evaluation model=gpt-4o, reason=The score is 1.00 because the relevant nodes, offering essential data for comparing cargo traffic in the Suez and Panama Canals in 2019, are perfectly ranked at the top. These nodes effectively deliver a comprehensive breakdown of cargo volumes through both canals during that year, ensuring accurate comparisons can be made efficiently., error=None)
| PASSED | ||
Contextual Recall | 1.0 (threshold=0.5, evaluation model=gpt-4o, reason=The score is 1.00 because every sentence in the expected output aligns perfectly with the data from the nodes in the retrieval context, effectively illustrating the significant difference in cargo volumes handled by both canals. Well done on maintaining precise and accurate attention to detail!, error=None)
| PASSED | ||
Contextual Relevancy | 0.95 (threshold=0.5, evaluation model=gpt-4o, reason=The score is 0.95 because although the context is rich with detailed data on Suez Canal cargo traffic, it lacks specific information on the Panama Canal’s cargo traffic, necessitating additional data for a complete comparison., error=None)
| PASSED | ||
Faithfulness | 1.0 (threshold=0.5, evaluation model=gpt-4o, reason=Awesome job! The score is 1.00 because there are no contradictions present, showcasing perfect alignment and faithfulness of the actual output to the retrieval context. Keep up the excellent work!, error=None)
| PASSED |
Ocena modeli Retrieval-Augmented Generation (RAG) wymaga ustrukturyzowanego podejścia, które zapewnia zarówno precyzję wyszukiwania, jak i wiarygodność odpowiedzi. LLM-as-a-Judge stanowi efektywną alternatywę dla oceny ludzkiej, umożliwiając systematyczną analizę wyników na podstawie wcześniej zdefiniowanych kryteriów, co przekłada się na skalowalność i redukcję kosztów walidacji.
Korzystając z DeepEval, przetestowaliśmy naszego asystenta AI SeaStat pod kątem kluczowych metryk, takich jak Correctness (G-Eval), Answer Relevancy, Contextual Precision, Contextual Recall, Contextual Relevancy oraz Faithfulness. Wyniki testów wykazały drobne rozbieżności w wartościach liczbowych, brak niektórych kontekstowych informacji oraz niewielkie niedokładności w precyzji wyszukiwania – informacje te są kluczowe dla dalszej optymalizacji modelu.
Te obserwacje podkreślają, że nawet wysokowydajne modele RAG wymagają rygorystycznej ewaluacji, aby zapewnić poprawność faktograficzną i uniknąć potencjalnie wprowadzających w błąd odpowiedzi. Automatyzacja tego procesu umożliwia ciągłe doskonalenie modeli, zapewniając, że asystenci AI dostarczają rzetelne i kontekstowo trafne informacje na dużą skalę.
Asystenci AI to technologia, która wkrótce stanie się nieodzownym narzędziem dla pracowników na wszystkich szczeblach organizacji – od kadry zarządzającej po specjalistów. Ich dynamiczny rozwój pozwala na błyskawiczne dostosowanie się do potrzeb biznesowych oraz zmieniających się oczekiwań użytkowników.