

Lokalne wdrażanie dużych modeli językowych (LLM) staje się coraz bardziej popularne wśród programistów, entuzjastów technologii oraz specjalistów z branż takich jak ubezpieczenia czy transport. W przeciwieństwie do rozwiązań opartych na chmurze, lokalne wdrażanie LLM-ów zapewnia większą prywatność, dostępność offline oraz pełną kontrolę nad optymalizacją zasobów i wydajnością działania modelu.
Uruchamianie modeli takich jak Llama 2 czy Mistral bezpośrednio na własnym sprzęcie oznacza, że dane pozostają na Twoim urządzeniu — co jest idealnym rozwiązaniem w przypadku zadań wymagających wysokiego poziomu prywatności, takich jak przetwarzanie dokumentów ubezpieczeniowych czy praca z zastrzeżonymi danymi transportowymi. Przy okazji nie ponosisz stałych kosztów związanych z API, a wydajność zależy wyłącznie od Twojego systemu. Niezależnie od tego, czy tworzysz własnego chatbota, agenta, asystenta programistycznego opartego na AI, czy analizujesz dokumenty offline — lokalne wdrożenie daje Ci swobodę eksperymentowania i wprowadzania innowacji bez konieczności polegania na zewnętrznych usługach.
W tym przewodniku przyjrzymy się dwóm zaawansowanym narzędziom, które umożliwiają lokalne uruchamianie modeli: Ollama i LM Studio. Przejdziemy przez proces instalacji, omówimy sposób ich użycia oraz możliwości dostosowania, pomagając Ci wybrać najlepsze rozwiązanie dopasowane do Twoich potrzeb.
Pierwsze kroki z Ollama (narzędzie CLI)
Ollama to wydajne, otwartoźródłowe narzędzie konsolowe do lokalnego uruchamiania modeli LLM. Działa jako menedżer modeli i środowisko wykonawcze, ułatwiając pobieranie i uruchamianie modeli open source (takich jak Llama 2, Mistral, CodeLlama itp.) bezpośrednio na Twoim komputerze. Ollama jest dostępna dla systemów macOS, Linux i Windows, a dodatkowo oferuje lokalne API REST do integracji z aplikacjami.
Zainstaluj Ollama na swoim systemie: Pobierz instalator dla swojego systemu operacyjnego ze strony internetowej Ollama lub skorzystaj z menedżera pakietów.
W systemie Windows pobierz plik OllamaSetup.exe ze strony internetowej i uruchom go.
W systemie Linux możesz zainstalować Ollama za pomocą jednej komendy:
curl -fsSL https://ollama.com/install.sh | sh
Po zakończeniu instalacji otwórz terminal (lub wiersz poleceń w systemie Windows) i sprawdź, czy Ollama zostało poprawnie zainstalowane, wyświetlając jego wersję:
ollama --version
Powinno to wyświetlić zainstalowaną wersję Ollama, co potwierdzi, że narzędzie jest gotowe do użycia, np.:
ollama version is 0.6.2
Pobierz model LLM („ściągnij” model): Ollama zawiera wbudowaną bibliotekę modeli. Możesz przeszukiwać katalog dostępny na stronie internetowej lub po prostu pobrać znany model, podając jego nazwę.
Na przykład, aby pobrać model Llama 2 Chat (7B), użyj polecenia:
ollama pull llama2:7b-chat
To polecenie pobiera na Twój komputer pliki modelu (może to chwilę potrwać, ponieważ mają one zazwyczaj kilka gigabajtów). Model wystarczy pobrać tylko raz — zostaje zapisany lokalnie. W razie potrzeby możesz wyświetlić listę wszystkich pobranych modeli za pomocą polecenia ollama list.
Uruchom model lokalnie: Po pobraniu możesz uruchomić model za pomocą polecenia
ollama run. Spowoduje to uruchomienie interaktywnej sesji, w której możesz wpisywać zapytania i otrzymywać odpowiedzi. Na przykład:
ollama run llama2:7b-chat >>> What is the capital city of Poland?
Po uruchomieniu powyższego polecenia Ollama załaduje model, a na ekranie pojawi się znak >>>. Możesz wtedy wpisywać pytania lub polecenia. Model (w tym przypadku Llama 2 7B Chat) będzie generował odpowiedź na każde zapytanie. Na przykład możesz zapytać: „What is the capital of France?” i otrzymać odpowiedź: „Paris is the capital of France.” wyświetloną w terminalu.
Przy pierwszym uruchomieniu inicjalizacja modelu może chwilę potrwać, ale kolejne zapytania są obsługiwane szybciej, bez ponownego ładowania modelu.
Wskazówka: Możesz też przekazać jednorazowe zapytanie bezpośrednio w poleceniu, np. ollama run llama2:7b "What is the capital city of Poland?" spowoduje wygenerowanie jednej odpowiedzi i powrót do powłoki systemowej.
Możesz także uruchomić Ollama jako serwer w tle za pomocą polecenia ollama serve. Umożliwia to korzystanie z API REST dostępnego pod adresem localhost:11434, które deweloperzy mogą wykorzystać do integracji modelu z aplikacjami za pomocą zapytań HTTP. Możesz zadawać pytania modelowi, wysyłając zapytania POST, na przykład:
curl http://localhost:11434/api/generate -d '{
"model": "llama2:7b-chat",
"prompt": "What is the capital city of Poland?"
}'
API zwraca odpowiedź w postaci obiektów JSON, w miarę jak model stopniowo ją generuje. Każdy obiekt zawiera fragment tekstu (ang. chunk).
{
"model": "llama2:7b-chat",
"created_at": "2025-04-02T15:19:17.1569954Z",
"response": "The",
"done": false
}
{
"model": "llama2:7b-chat",
"created_at": "2025-04-02T15:19:17.268992Z",
"response": " capital",
"done": false
}
{
"model": "llama2:7b-chat",
"created_at": "2025-04-02T15:19:17.3796491Z",
"response": " city",
"done": false
}
...
{
"model": "llama2:7b-chat",
"created_at": "2025-04-02T15:19:21.3106413Z",
"response": " Warszawa",
"done": false
}
{
"model": "llama2:7b-chat",
"created_at": "2025-04-02T15:19:21.4619772Z",
"response": ").",
"done": false
}
{
"model": "llama2:7b-chat",
"created_at": "2025-04-02T15:19:21.6296267Z",
"response": "",
"done": true,
"done_reason": "stop",
"total_duration": 5337417000,
"load_duration": 8625100,
"prompt_eval_count": 28,
"prompt_eval_duration": 854952300,
"eval_count": 15,
"eval_duration": 4472807400
}
Jeśli ustawisz stream: false, odpowiedź zostanie zwrócona jako pojedynczy obiekt JSON.
curl http://localhost:11434/api/generate -d '{
"model": "llama2:7b-chat",
"prompt": "What is the capital city of Poland?",
"stream": false
}
Możesz również ustawić różne parametry modelu, takie jak temperatura (czyli poziom losowości generowanych odpowiedzi), dodając odpowiednie pola w opcjach.
curl http://localhost:11434/api/generate -d '{
"model": "llama2:7b-chat",
"prompt": "What is the capital city of Poland?",
"options": {
"temperature": 0.2
}
"stream": false
}'
Dostosuj modele: Ollama obsługuje pliki Modelfile o składni podobnej do Dockerfile, które umożliwiają tworzenie własnych wariantów modeli LLM. Dzięki niej możesz:
- Rozpocząć od istniejącego modelu (np. llama3)
- Dodać własne systemowe prompt’y
- Wprowadzić dane zdefiniowane przez użytkownika (np. instrukcje, kontekst)
- Ustawić parametry modelu, takie jak temperatura
Oto prosty przykład, jak możesz stworzyć własnego asystenta do przetwarzania dokumentów ubezpieczeniowych:
FROM llama2:7b-chat
PARAMETER temperature 0.7
SYSTEM """
You are an assistant that extracts insurance-related information from a given input text.
You must extract and return only the following fields:
- policy_number
- insurance_period
- insured (company or person name)
- nip (tax identification number)
- address (of the insured)
Return the output as a **clean JSON object** -- not as a string, not inside quotes, and without any commentary. If a field is missing, use "Not found".
Example output format:
{
"policy_number": "...",
"insurance_period": "...",
"insured": "...",
"nip": "...",
"address": "..."
}
"""
TEMPLATE """
{{ .System }}
Input:
{{ .Prompt }}
Response:
""" Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.
Aby skorzystać z pliku Modelfile, zapisz go w wybranym katalogu, np. insurance-assistant, a następnie utwórz własny model za pomocą polecenia:
ollama create insurance-assistant -f insurance-assitant/Modelfile
Następnie możesz użyć swojego modelu, podając właściwą nazwę modelu w zapytaniu:
curl http://localhost:11434/api/generate -d '{
"model": "insurance-extractor",
"prompt": "",
"stream": false
}'
Ollama działa wyłącznie w trybie konsolowym — nie posiada graficznego interfejsu użytkownika. Jednak dzięki temu świetnie sprawdza się w automatyzacji: możesz przekierowywać dane wejściowe i wyjściowe, zapisywać odpowiedzi do plików lub korzystać z API Ollama bezpośrednio w kodzie.
Podsumowując, za pomocą zaledwie kilku poleceń możesz uruchomić lokalnie model LLM, który chroni prywatność, działa bez połączenia z internetem i jest gotowy do odpowiadania na pytania lub wspierania Cię w pracy programistycznej.
Pierwsze kroki z LM Studio (aplikacja desktopowa)
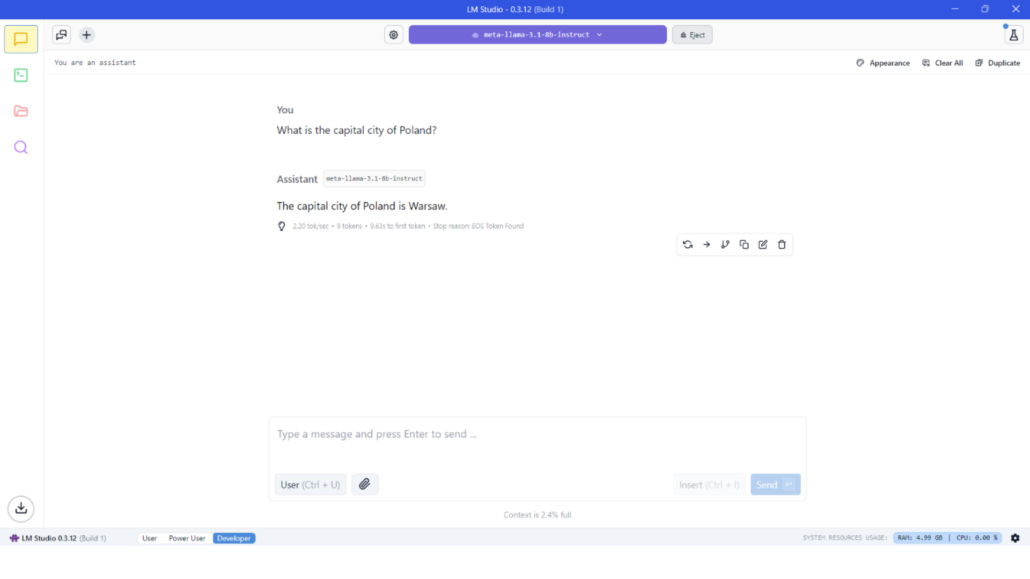
LM Studio to przyjazna dla użytkownika aplikacja desktopowa, która umożliwia pobieranie i uruchamianie lokalnych modeli LLM za pomocą interfejsu graficznego. Działa na wielu platformach (Windows, macOS, Linux) i jest idealna dla początkujących, którzy wolą nie korzystać z konsoli. Dzięki LM Studio możesz rozmawiać z modelami w estetycznym interfejsie, zarządzać pobieraniem modeli, a także uruchomić lokalny serwer, by wykorzystywać model w innych aplikacjach.
To polecenie pobiera pliki modelu na Twój komputer (może to potrwać, ponieważ modele mają zazwyczaj kilka gigabajtów). Model wystarczy pobrać tylko raz — później jest przechowywany lokalnie. W razie potrzeby możesz wyświetlić listę wszystkich pobranych modeli za pomocą polecenia ollama list.
- Zainstaluj i uruchom LM Studio: Pobierz instalator dla swojego systemu operacyjnego ze strony LM Studio i zainstaluj aplikację. Po zakończeniu instalacji uruchom LM Studio. Przy pierwszym uruchomieniu zostaniesz poproszony o pobranie modelu AI. Możesz wybrać jeden z popularnych modeli open source z dostępnej listy. Na początek możesz na przykład wybrać mniejszy model, taki jak „Mistral 7B” lub wariant Llama2 dostosowany do instrukcji.
Uruchom swoją pierwszą rozmowę: Gdy model zostanie pobrany, LM Studio załaduje go do pamięci. Następnie możesz rozpocząć nową sesję czatu w aplikacji. Interfejs zazwyczaj zawiera pole tekstowe, w którym wpisujesz zapytanie lub polecenie, a odpowiedź modelu pojawia się w oknie rozmowy. Wystarczy, że wpiszesz pytanie (na przykład: „Jaka jest stolica Francji?” albo „Wyjaśnij mechanikę kwantową w prosty sposób”) i naciśniesz Enter. Odpowiedź AI zostanie wyświetlona jako odpowiedź „Asystenta” w czacie.
LM Studio w przejrzysty sposób pokazuje również metryki generowania odpowiedzi.
liczba tokenów wejściowych i wyjściowych,
tokeny na sekundę – możesz zobaczyć, jak szybko model generuje tekst,
zajętość kontekstu,
wykorzystanie zasobów systemowych (RAM i użycie procesora).
Odkryj dostępne funkcje: Graficzny interfejs LM Studio oferuje dodatkowe możliwości dostępne zarówno dla początkujących, jak i zaawansowanych użytkowników:
Biblioteka modeli: Sekcja „Odkrywaj modele” lub katalog, w którym możesz pobierać nowe modele lub aktualizować już posiadane. Nie jesteś ograniczony do jednego modelu — możesz przechowywać wiele modeli i swobodnie się między nimi przełączać. Oznacza to szeroki wybór: od małych modeli z 3 miliardami parametrów, zapewniających szybkość działania, aż po modele 70-miliardowe, jeśli Twój system jest w stanie je obsłużyć.
Interfejs czatu: Główne okno czatu (jak pokazano wcześniej) to miejsce, w którym prowadzisz interakcję z modelem. Każde nowe zapytanie, które wpiszesz, jest traktowane jako część rozmowy i otrzymuje odpowiedź w formacie konwersacyjnym. Możesz prowadzić wieloetapowy dialog — tak jak w rozmowie z ChatGPT. Nie musisz samodzielnie zarządzać historią zapytań — aplikacja automatycznie zachowuje kontekst rozmowy.
Ustawienia zaawansowane: W panelu bocznym LM Studio udostępnia opcje konfiguracji dla użytkowników, którzy chcą mieć większą kontrolę nad działaniem modelu. Możesz ustawić systemowy prompt (czyli rolę lub instrukcję, która globalnie wpływa na zachowanie AI), dostosować parametry generowania, takie jak temperatura (twórczość vs. spójność), top-p lub top-k (do kontrolowania losowości), maksymalna liczba tokenów w odpowiedzi itd. Te ustawienia pozwalają precyzyjnie dostosować sposób działania modelu — bez potrzeby pisania kodu.
Na przykład możesz ustawić instrukcję systemową typu: „Jesteś pomocnym asystentem programisty”. To przystępny sposób na personalizację zachowania modelu, choć nie tak rozbudowany jak możliwości oferowane przez narzędzie konsolowe.
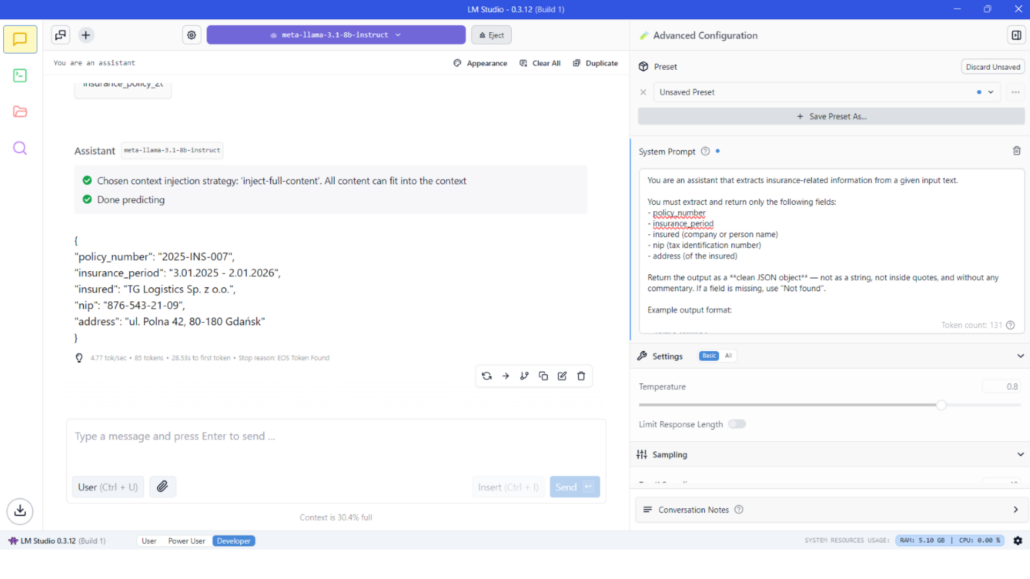
Ustawienia zaawansowane – prosty przykład asystenta AI do przetwarzania dokumentów ubezpieczeniowych.
Lokalny serwer API: Dla deweloperów LM Studio oferuje tryb „Local LLM Server”. Wystarczy przełączyć się na zakładkę Developer, wybrać model i kliknąć przycisk Start. Włącza to punkt końcowy API na
localhost, który imituje API OpenAI, co pozwala innym programom wysyłać zapytania do lokalnie uruchomionego modelu.To bardzo przydatne rozwiązanie, jeśli chcesz zintegrować lokalny model LLM z własnymi aplikacjami (na przykład podłączając interfejs czatu lub wykorzystując model do funkcji AI w środowisku IDE), zachowując jednocześnie prywatność i uniezależniając się od usług zewnętrznych.
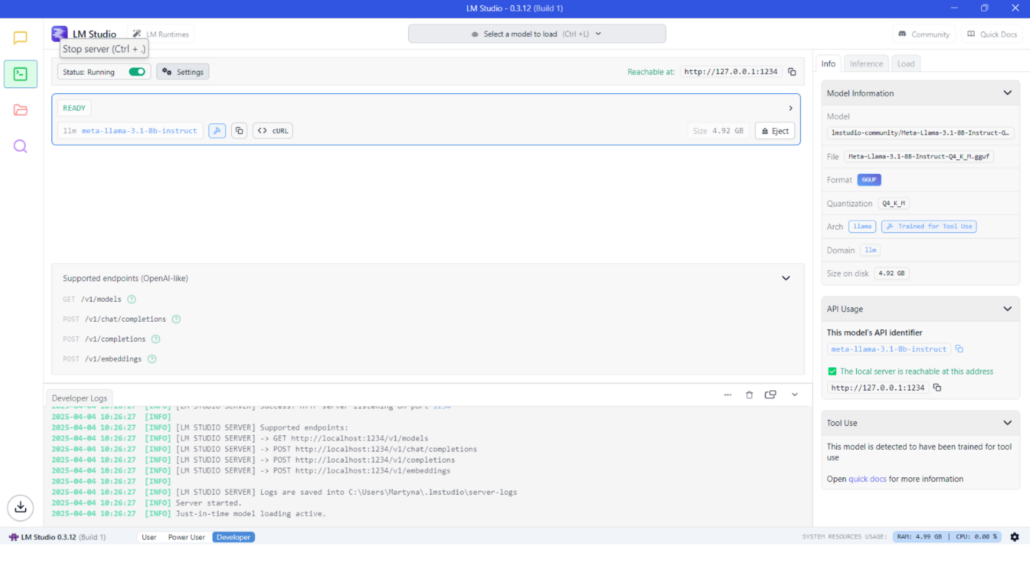
Zakładka Developer – umożliwia uruchomienie lokalnego serwera LLM, hostującego Twój spersonalizowany model.
Korzystanie z LM Studio jest równie proste jak w przypadku ChatGPT — wpisujesz zapytanie i otrzymujesz odpowiedź — z tą różnicą, że wszystko działa lokalnie na Twoim sprzęcie. Przyjazny interfejs użytkownika obniża próg wejścia, ponieważ nie musisz używać konsoli ani pamiętać poleceń. Otrzymujesz natychmiastowe, interaktywne odpowiedzi AI, a wszystkim możesz wygodnie zarządzać za pomocą przycisków i menu.
Ollama vs. LM Studio: porównanie narzędzi
Zarówno Ollama, jak i LM Studio umożliwiają lokalne uruchamianie modeli LLM, jednak są skierowane do nieco innych grup użytkowników i przypadków użycia. Oto porównanie kluczowych aspektów, które pomoże zrozumieć różnice między tymi narzędziami:
Interfejs i łatwość obsługi:
LM Studio oferuje dopracowany graficzny interfejs użytkownika, co czyni je wyjątkowo przystępnym dla początkujących. Obsługa odbywa się metodą „wskaż i kliknij”, z wbudowanym oknem czatu, dzięki czemu nie jest wymagana żadna wiedza techniczna, aby rozpocząć pracę.Ollama z kolei to narzędzie konsolowe (CLI) z opcjonalnym API REST. Daje dużą moc i elastyczność, ale wymaga swobody w korzystaniu z terminala, aby w pełni wykorzystać jego możliwości. Początkujący mogą uznać krzywą uczenia się Ollamy za bardziej stromą, podczas gdy LM Studio sprawia wrażenie rozwiązania typu „podłącz i używaj”.
Obsługiwane modele:
Oba narzędzia obsługują szeroką gamę otwartoźródłowych modeli LLM. LM Studio może ładować dowolny model w formacie GGUF (standard używany przezllama.cpp), co oznacza, że możesz korzystać z modeli takich jak Llama 2 (7B, 13B, 70B), Mistral, Vicuna, Alpaca, CodeLlama i wielu innych — o ile Twój sprzęt jest w stanie je obsłużyć.
Odpowiednie zastosowania:
Ze względu na powyższe różnice, LM Studio świetnie sprawdzi się u użytkowników, którzy chcą mieć na swoim komputerze osobistego asystenta w stylu ChatGPT, bez potrzeby skomplikowanej konfiguracji. To dobre rozwiązanie do interaktywnych pytań i odpowiedzi, burzy mózgów czy codziennego, swobodnego użytkowania — uruchamiasz, gdy potrzebujesz, wpisujesz zapytanie, otrzymujesz odpowiedź.Ollama natomiast jest idealna dla programistów oraz osób, które chcą zintegrować modele LLM ze swoimi projektami lub procesami. Jeśli planujesz eksperymentować z promptami w skryptach, dostosowywać zachowanie modelu lub budować aplikację (np. chatbota, integrację asystenta kodu itp.), interfejs CLI i API Ollamy daje Ci elastyczność potrzebną do takich zastosowań.
Wnioski i rekomendacje
Lokalne wdrażanie modeli LLM oferuje wiele możliwości dla programistów i entuzjastów. Omówiliśmy Ollama i LM Studio – dwa doskonałe narzędzia, które umożliwiają dostęp do lokalnej sztucznej inteligencji. Oto krótkie podsumowanie wskazówek dotyczących wyboru między nimi:
- Wybierz LM Studio, jeśli chcesz gotowe rozwiązanie do rozmów z AI z przyjaznym interfejsem graficznym. To idealna opcja dla początkujących lub osób, które nie chcą korzystać z konsoli. Oferuje szybkie uruchomienie, łatwe pobieranie modeli i wygodny interfejs czatu do interakcji z AI. Świetnie sprawdzi się jako „offline’owy ChatGPT” do użytku osobistego, robienia notatek czy generowania pomysłów — bez konieczności zagłębiania się w konfigurację. To także wygodny sposób na zaprezentowanie możliwości LLM osobom nietechnicznym, ponieważ aplikacja działa jak zwykły program.
Wybierz Ollama, jeśli zależy Ci na większej kontroli, automatyzacji lub integracji. Deweloperzy i zaawansowani użytkownicy docenią jej elastyczność — możesz ją skryptować, uruchamiać bez interfejsu na serwerze, integrować lokalny model LLM z własnymi aplikacjami przez API oraz dostosowywać zachowanie modeli za pomocą plików Modelfile. Jeśli dobrze czujesz się w pracy z konsolą i chcesz precyzyjnie kontrolować sposób działania AI (poza tym, co oferuje interfejs graficzny), Ollama będzie lepszym wyborem. To także lekkie narzędzie, jeśli planujesz uruchamiać usługi AI w tle w sposób ciągły.
Na koniec pamiętaj, że sam model LLM, który wybierzesz, jest równie istotny jak narzędzie. Warto poświęcić czas na znalezienie modelu dopasowanego do konkretnego zadania — niezależnie od tego, czy potrzebujesz zwięzłego narzędzia do podsumowań, czy kreatywnego opowiadacza historii — i dostosowanego do możliwości Twojego sprzętu. Zarówno Ollama, jak i LM Studio umożliwiają łatwą zamianę modeli, więc nie jesteś ograniczony do jednego wyboru. Ekosystem otwartoźródłowych modeli rozwija się bardzo szybko, co oznacza, że uruchamianie zaawansowanej AI na własnym urządzeniu staje się coraz prostsze i powszechniejsze.
Podsumowując, lokalne wdrażanie modeli LLM za pomocą omawianych w tym tekście narzędzi daje Ci to, co najlepsze z obu światów: możliwości sztucznej inteligencji porównywalne z usługami chmurowymi, ale z zachowaniem prywatności, pełną kontrolą i bez żadnych stałych kosztów. Niezależnie od tego, czy wybierzesz zaawansowane narzędzie konsolowe, takie jak Ollama, czy przyjazną aplikację graficzną, jak LM Studio — dołączasz do czołówki rozwoju lokalnej AI.
Powodzenia w eksperymentach i udanego korzystania z własnego, lokalnego asystenta AI!