

Uruchamianie dużych modeli językowych (LLM) na własnym sprzęcie staje się coraz bardziej dostępne dzięki tzw. lekkim modelom LLM — modelom o stosunkowo niewielkiej liczbie parametrów, które zapewniają wysoką wydajność bez potrzeby korzystania z kart graficznych klasy serwerowej. W tym wpisie przyjrzymy się kilku najlepszym otwartoźródłowym lekkim modelom LLM oraz sposobom ich uruchamiania na lokalnym komputerze z systemem Windows — zarówno przy użyciu samego CPU, jak i z ograniczoną kartą graficzną (GPU) — w zastosowaniach związanych z przetwarzaniem dokumentów. Opisaliśmy także benchmark, który porównuje modele pod względem dokładności i szybkości wnioskowania, co pomoże Ci wybrać odpowiedni model do lokalnego środowiska i konkretnego przypadku użycia.
Lekkie modele LLM – czym są i czy warto uruchamiać je lokalnie?
„Lekkie” modele LLM to zazwyczaj modele mieszczące się w przedziale od około 1 do 8 miliardów parametrów — znacznie mniejsze niż modele klasy GPT-3 — często zoptymalizowane do działania na jednej karcie graficznej (GPU) lub nawet samym procesorze (CPU). Zazwyczaj są one udostępniane jako modele otwarte, z publicznie dostępnymi wagami. Tego typu rozwiązania rezygnują z części mocy obliczeniowej na rzecz większej efektywności, jednak dzięki postępom badawczym i przemyślanej inżynierii (lepsze dane, trenowanie z użyciem destylacji, wydajne mechanizmy uwagi itd.) ich możliwości znacząco wzrosły. Wiele z tych modeli dorównuje dziś, a nawet przewyższa znacznie większe modele w wybranych benchmarkach.
Lokalne uruchamianie takich modeli ma wiele zalet:
- Prywatność i bezpieczeństwo: Wszystkie dane pozostają na Twoim urządzeniu, co ma kluczowe znaczenie w przypadku poufnych dokumentów, takich jak umowy ubezpieczeniowe. Nie wysyłasz wrażliwych treści do zewnętrznego API.
- Oszczędność kosztów: Po pobraniu model działa lokalnie za darmo — bez opłat za korzystanie z API czy zasoby chmurowe. Przy regularnym przetwarzaniu dużej liczby dokumentów może to oznaczać znaczące oszczędności.
- Niskie opóźnienia i dostęp offline: Lokalna inferencja eliminuje opóźnienia sieciowe. Na GPU odpowiedzi mogą pojawiać się niemal natychmiast, a cały system może działać w trybie offline. To szczególnie przydatne w środowiskach lokalnych lub tam, gdzie dostęp do internetu jest ograniczony.
- Możliwość dostosowania: Korzystając z modeli lokalnych, masz pełną kontrolę — możesz zmieniać parametry, prompty lub dostrajać model do specyfiki swojej branży (np. danych ubezpieczeniowych) bez ograniczeń narzuconych przez dostawcę.
Krótko mówiąc, lekkie modele LLM dają Ci dostęp do możliwości sztucznej inteligencji bezpośrednio na Twoim sprzęcie. W dalszej części porównamy wybrane otwarte modele, które szczególnie dobrze sprawdzają się w lokalnym przetwarzaniu dokumentów.
Porównanie najlepszych lekkich modeli LLM
Lekkie, otwartoźródłowe duże modele językowe (LLM) stają się praktycznym wyborem dla organizacji, które chcą uruchamiać zadania AI lokalnie. Oferują one korzystny kompromis między wydajnością, szybkością a wymaganiami sprzętowymi — co czyni je idealnym rozwiązaniem do podsumowywania, ekstrakcji i klasyfikacji dokumentów bez potrzeby korzystania z infrastruktury chmurowej.
Skupimy się na następujących otwartoźródłowych modelach (każdy z dostępem do punktów kontrolnych do pobrania), które cieszą się dobrą opinią pod względem jakości w stosunku do swojej wielkości:
- Llama 3.1 – 8B parametrów (Meta AI)
- StableLM Zephyr – 3B parametrów (Stability AI)
- Llama 3.2 – 1B/3B parametrów (Meta AI)
- Mistral – 7B parametrów (Mistral AI)
- Gemma 3 – warianty 1B i 4B (Google DeepMind)
- DeepSeek R1 – warianty 1.5B i 7B (DeepSeek AI)
- Phi-4 Mini – 3.8B parametrów (Microsoft)
- TinyLlama – 1.1B parametrów (community project)
- Te modele obejmują zakres od bardzo małych (poniżej 1 GB na dysku) do średniej wielkości (około 5 GB). Wszystkie mogą być uruchamiane w trybie inferencji na karcie graficznej z 16 GB pamięci (często nawet w wersji z obniżoną precyzją lub skwantyzowanej do 4 bitów), a wiele z nich działa również na procesorze, o ile dysponujemy odpowiednią ilością pamięci RAM i cierpliwością. Tabela 1 przedstawia ich charakterystyki.
| Model | Rozmiar na dysku (po kwantyzacji) | Maksymalny kontekst | Licencja |
|---|---|---|---|
| Llama 3.1 (8B) | 4,9 GB | 128 tys. tokenów | Open-source |
| StableLM Zephyr (3B) | 1,6 GB | 4 tys. tokenów | Tylko do użytku niekomercyjnego |
| Llama 3.2 (3B) | 2,0 GB | 128 tys. tokenów | Open-source |
| Mistral (7B) | 4,1 GB | 32 tys. tokenów | Open-source (licencja Apache 2.0) |
| Gemma 3 (4B) | 3,3 GB | 128 tys. tokenów | Open-source |
| Gemma 3 (1B) | 0,8 GB | 32 tys. tokenów | Open-source |
| DeepSeek R1 (7B) | 4,7 GB | 128 tys. tokenów | Open-source (licencja MIT) |
| DeepSeek R1 (1.5B) | 1,1 GB | 128 tys. tokenów | Open-source (licencja MIT) |
| Phi-4 Mini (3.8B) | 2,5 GB | 128 tys. tokenów | Open-source |
| TinyLlama (1.1B) | 0,6 GB | 2 tys. tokenów | Open-source |
Tabela 1: Lekkie modele LLM do użytku lokalnego – rozmiary modeli i maksymalne okno kontekstu.
Uwaga: „Maksymalny kontekst” to maksymalna długość sekwencji (w tokenach), jaką model może przetworzyć jednorazowo.
Przyjrzyjmy się teraz zaletom i ograniczeniom każdego z modeli, szczególnie w kontekście zadań związanych z dokumentami.
- Llama 3.1 (8B): Wszechstronny, wydajny model ogólnego zastosowania; umiarkowany rozmiar i dobre możliwości wielojęzyczne. Zbyt ciężki dla systemów opartych wyłącznie na CPU; wymaga dzielenia długich dokumentów na fragmenty.
- StableLM Zephyr (3B): Bardzo lekki model, sprawdza się w podstawowym QA i ekstrakcji. Ograniczony przez niewielką liczbę parametrów i restrykcyjną licencję komercyjną.
- Llama 3.2 (3B): Doskonały do podsumowań i wyszukiwania informacji; obsługuje długi kontekst (128 tys. tokenów). Mniejszy rozmiar wpływa na precyzję w złożonym rozumowaniu.
- Mistral (7B): Najlepszy ogólny model w swojej klasie; bardzo wydajna inferencja. Idealny do szczegółowych zadań podsumowujących.
- Gemma 3 (4B/1B): Oferuje możliwości multimodalne i szerokie wsparcie językowe. Wariant 4B to dobry kompromis między mocą a szybkością, wariant 1B najlepiej sprawdza się w prostych zadaniach.
- DeepSeek R1 (7B/1.5B): Zrównoważona wydajność i rozumienie ogólnych zadań NLP; słabsze wnioskowanie w porównaniu do Mistrala.
- Phi-4 Mini (3.8B): Wyjątkowe zdolności analityczne, matematyczne i logiczne; idealny do analitycznego przetwarzania dokumentów. Skoncentrowany głównie na języku angielskim.
- TinyLlama (1.1B): Bardzo lekki model; odpowiedni do prostych zadań ekstrakcji i klasyfikacji tekstu. Ograniczone rozumienie kontekstu.
Omówione powyżej modele obejmują szeroki zakres rozmiarów i możliwości. Większe warianty, takie jak Llama 3.1 i Mistral, dobrze radzą sobie ze złożonymi zadaniami podsumowania i obsługą wielu języków, ale mniej nadają się do systemów opartych wyłącznie na CPU. Modele średniej wielkości, takie jak Llama 3.2 i Gemma 3 (4B), efektywnie przetwarzają długie dane wejściowe, oferując przy tym rozsądną wydajność. Mniejsze modele, w tym TinyLlama i StableLM Zephyr, są lekkie i szybkie, co czyni je praktycznym wyborem do prostych zadań ekstrakcji lub klasyfikacji.
Porównanie modeli: ekstrakcja i podsumowywanie dokumentów
Poniżej przedstawiamy prosty plan benchmarku modeli, obejmujący dwa typowe zadania związane z przetwarzaniem dokumentów:
- Ekstrakcja informacji: Ocenialiśmy, jak dobrze każdy model potrafi wyodrębnić konkretne pola z polisy lub certyfikatu. W szczególności prosiliśmy modele o znalezienie numeru polisy, nazwy ubezpieczonego, NIP-u, adresu oraz okresu ubezpieczenia w treści dokumentu i zwrócenie ustrukturyzowanego wyniku — czystej odpowiedzi w formacie JSON zawierającej wszystkie wymagane wartości.
- Podsumowanie: Każdy model generował zwięzłe podsumowanie polisy ubezpieczeniowej, obejmujące kluczowe informacje, takie jak zakres ochrony, wyłączenia i warunki. Podsumowania ocenialiśmy pod względem przejrzystości, poprawności, zgodności z faktami i czytelności, a za zmyślanie informacji przyznawaliśmy znaczące kary.
Wykorzystaliśmy 11 dokumentów i przeprowadziliśmy wszystkie testy za pomocą Ollama (więcej o uruchamianiu modeli z użyciem Ollama możesz przeczytać tutaj). Benchmarki zostały wykonane na komputerze z kartą graficzną NVIDIA GeForce RTX 2060 z 6 GB pamięci VRAM. Aby zapewnić spójność wyników, każdy model był uruchamiany z temperaturą ustawioną na 0 w zadaniu ekstrakcji (dla uzyskania deterministycznych odpowiedzi) oraz z ustaloną temperaturą 0,7 w zadaniu podsumowania. W przypadku ekstrakcji wykorzystaliśmy również ustrukturyzowane odpowiedzi:
"stream": false,
"format": {
"type": "object",
"properties": {
"numer_polisy": {
"type": "string"
},
"okres_ubezpieczenia_od": {
"type": "string"
},
"okres_ubezpieczenia_do": {
"type": "string"
},
"ubezpieczony": {
"type": "string"
},
"nip_ubezpieczonego": {
"type": "string"
},
"adres_ubezpieczonego": {
"type": "string"
}
},
"required": [
"numer_polisy",
"okres_ubezpieczenia_od",
"okres_ubezpieczenia_do",
"ubezpieczony",
"nip_ubezpieczonego",
"adres_ubezpieczonego"
]
}
}

Przykłady certyfikatów ubezpieczeniowych.
Tabela poniżej przedstawia wyniki benchmarku. Dokładność ekstrakcji odnosi się do liczby dokumentów (z 11), w których model poprawnie wyodrębnił wszystkie kluczowe pola. Tokeny/sek to szybkość wnioskowania modelu — czyli tempo generowania odpowiedzi.
| Model | Podsumowanie | Dokładność ekstrakcji | Tokeny/sek. |
|---|---|---|---|
| Llama 3.1 (8B) | Wysoka jakość, brak halucynacji | 10/11 | 13.49 |
| StableLM 3B | Średnia jakość, literówki/halucynacje | 4/11 | 56.51 |
| Llama 3.2 (3B) | Zwięzłe i pełne podsumowanie, brak halucynacji | 8/11 | 49.49 |
| Mistral 7B | Rozbudowane podsumowanie, zgodne z faktami | 8/11 | 29.01 |
| Gemma 3 4B | Zwięzłe i pełne podsumowanie, brak halucynacji | 10/11 | 13.37 |
| Gemma 3 1B | Zwięzłe i pełne podsumowanie, brak halucynacji | 4/11 | 73.46 |
| DeepSeek 7B | Zwięzłe i pełne podsumowanie, brak halucynacji | 6/11 | 16.39 |
| DeepSeek 1.5B | Bardzo słaba jakość, częste halucynacje/błędy | 0/11 | 66.45 |
| Phi-4 Mini 3.8B | Bardzo zwięzłe podsumowania, zgodne z faktami | 9/11 | 39.31 |
| TinyLlama 1.1B | Słaba jakość, poważne halucynacje | 2/11 | 107.34 |
Tabela: Porównanie modeli
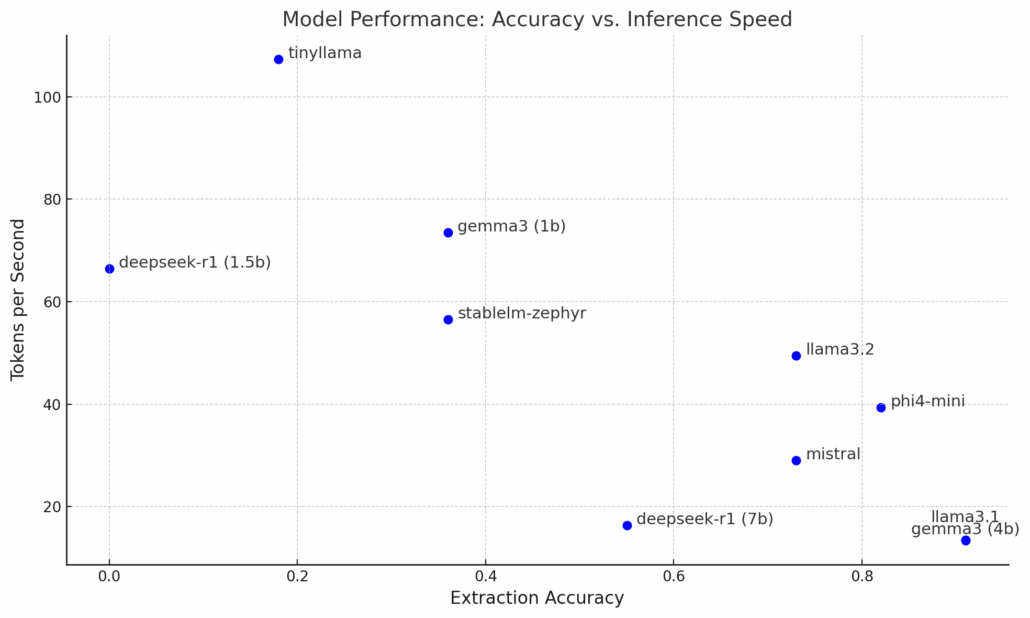
Ten wykres punktowy przedstawia kompromis między dokładnością ekstrakcji a szybkością wnioskowania (mierzoną w tokenach na sekundę).
Wyniki benchmarku ujawniają istotne różnice pomiędzy testowanymi modelami.
- Modele z dolnej prawej części wykresu — Llama 3.1 (8B), Gemma 3 (4B) i Phi-4 Mini (3.8B) — wyróżniają się wysoką jakością podsumowań i dokładnością ekstrakcji, konsekwentnie dostarczając zwięzłe i precyzyjne odpowiedzi. Phi-4 Mini wydaje się oferować dobry kompromis między szybkością a dokładnością.
- Modele takie jak Mistral 7B, DeepSeek 7B oraz Llama 3.2 generują szczegółowe i bogate w treść podsumowania, choć ich skuteczność w zadaniach ekstrakcji jest umiarkowana.
- Z kolei mniejsze modele (w lewej górnej części wykresu), takie jak StableLM Zephyr (3B), Gemma 3 (1B) i TinyLlama (1.1B), cechują się znacznie niższą dokładnością ekstrakcji i są podatne na częste halucynacje. Ich zaletą jest natomiast szybka inferencja. Ograniczone okna kontekstu (np. 4 tys. tokenów) mogą dodatkowo wpływać na obniżoną skuteczność. Ogólnie rzecz biorąc, modele te nadają się raczej do bardzo podstawowych zadań.
Dobór odpowiedniego modelu do Twoich potrzeb
Wybór modelu językowego do ekstrakcji lub podsumowywania dokumentów to kwestia znalezienia odpowiedniego balansu między dokładnością, szybkością działania a ograniczeniami sprzętowymi. Poniżej znajdziesz krótkie zestawienie, które pomoże Ci dobrać najlepsze rozwiązanie — niezależnie od tego, czy zależy Ci na wysokiej precyzji, szybkiej inferencji, czy lekkim modelu do podstawowych zadań.
Wysoka dokładność i rozsądna szybkość: Wybierz Phi-4 Mini (3.8B), Gemma 3 (4B) lub Llama 3.1 (8B), jeśli zależy Ci na solidnej dokładności ekstrakcji i podsumowań.
Szybka inferencja i umiarkowana dokładność: Postaw na Llama 3.2 (3B) lub StableLM Zephyr (3B) w przypadku prostszych zadań na sprzęcie o ograniczonych zasobach.
Zrównoważona wydajność (kompromis między dokładnością a szybkością): Mistral (7B) oferuje silne możliwości ogólnego zastosowania, dobrze sprawdzając się w szczegółowych zadaniach podsumowywania dokumentów.
Środowiska o niskich zasobach (zadania podstawowe): Rozważ TinyLlama (1.1B) do szybkiej ekstrakcji lub klasyfikacji na minimalnym sprzęcie, jeśli dokładność nie jest kluczowa.
Podsumowanie
Lekkie modele LLM stają się coraz bardziej dostępną opcją do lokalnego uruchamiania, szczególnie w branżach intensywnie pracujących z dokumentami, takich jak ubezpieczenia. Modele takie jak Phi-4 Mini, Gemma 3 (4B) czy Mistral 7B oferują wysoką wydajność w zadaniach podsumowywania, ekstrakcji i klasyfikacji. Odpowiednie zrównoważenie rozmiaru modelu, szybkości wnioskowania i dokładności pozwala osiągać optymalne rezultaty, dając organizacjom dostęp do niedrogich, prywatnych i responsywnych rozwiązań AI uruchamianych bezpośrednio na własnym sprzęcie.