

Zastanawiałeś się kiedyś, co dzieje się z Twoimi danymi, gdy korzystasz z chmurowych platform AI, albo czy informacje, które podajesz są wykorzystywane do trenowania przyszłych modeli? W tym artykule przedstawiamy zasady, dotyczące prywatności danych, obowiązujące w czołowych platformach AI. Dowiesz się także, co zrobić, aby Twoje dane nie były wykorzystywane do trenowania dużych modeli językowych (LLM).
Najwięksi dostawcy chmurowych usług AI stają się coraz bardziej transparentni w kwestii wykorzystywania danych – zwłaszcza w kontekście trenowania modeli. Choć większość platform, szczególnie tych oferujących usługi na poziomie korporacyjnym, domyślnie nie wykorzystuje Twoich danych wejściowych i wyjściowych do treningu, to szczegóły zapisane drobnym drukiem mają znaczenie. Zrozumienie, w jaki sposób te usługi przetwarzają dane – oraz jak możesz zachować nad nimi kontrolę – jest kluczowe.
Z tego bloga dowiesz się jakie zasady, dotyczące prywatności danych i trenowania modeli stosują najpopularniejsze platformy AI, takie jak OpenAI, Google Gemini, Azure OpenAI od Microsoftu oraz Claude firmy Anthropic. Z tekstu dowiesz się między innymi:
w jaki sposób platformy AI wykorzystują Twoje dane i czy są one domyślnie używane do trenowania modeli
jak, w razie potrzeby, uniemożliwić wykorzystywanie swoich danych przez AI (opcja opt-out)
gdzie przechowywane są Twoje dane (tzw. lokalizacja danych)
jakie środki zgodności z przepisami, takimi jak RODO, mają zastosowanie
Wdrażanie AI to nie tylko kwestia tworzenia promptów czy wydajności modeli. To również świadomość, gdzie trafiają Twoje dane – i jak zadbać o to, by pozostały pod Twoją kontrolą.
Oto, co warto wiedzieć:
OpenAI – Wykorzystanie danych i prywatność
OpenAI traktuje Twoje dane w różny sposób, w zależności od tego, jak korzystasz z jego usług:
Aplikacja ChatGPT (wersja webowa/mobilna)
Gdy prowadzisz rozmowy z ChatGPT, Twoje konwersacje mogą być wykorzystywane do trenowania modeli AI – chyba że ręcznie zrezygnujesz z tego (opt-out).
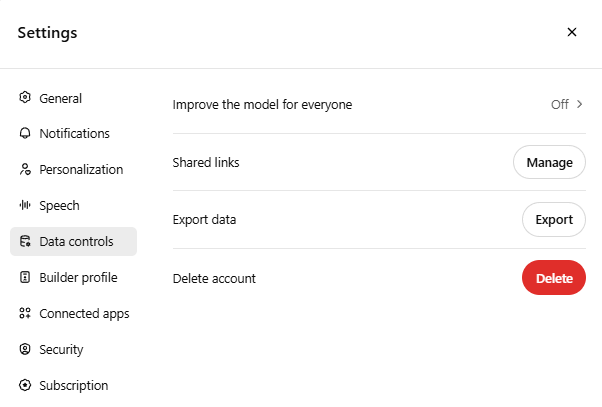
Aby zapobiec wykorzystywaniu Twoich danych:
- Przejdź do Ustawienia → Kontrola danych → Ulepszanie modelu dla wszystkich i wyłącz tę opcję.
- Nawet po rezygnacji (opt-out), OpenAI przechowuje rozmowy przez 30 dni w celu monitorowania nadużyć, a następnie je usuwa.
OpenAI API i ChatGPT Enterprise
Jeśli jesteś deweloperem lub firmą korzystającą z API OpenAI albo ChatGPT Enterprise, nie musisz rezygnować z udziału w trenowaniu modeli – domyślnie OpenAI nie wykorzystuje danych z API ani z wersji Enterprise do tego celu, a Twoje dane pozostają prywatne. Nie musisz podejmować żadnych dodatkowych działań – ochrona danych jest włączona automatycznie. Możesz zdecydować się na udostępnienie danych w celu ulepszania modeli, ale tylko jeśli tego chcesz.
Lokalizacja danych
Serwery OpenAI znajdują się głównie w Stanach Zjednoczonych i obecnie – jeśli korzystasz bezpośrednio z API – nie masz możliwości wyboru, gdzie Twoje dane są przechowywane. Oznacza to, że dane są przetwarzane w infrastrukturze OpenAI – objętej solidnymi zabezpieczeniami, ale niekoniecznie zlokalizowanej w Twoim kraju.
Są jednak postępy dla użytkowników biznesowych. OpenAI niedawno wprowadziło opcję dla wybranych klientów API w wersji Enterprise, która umożliwia przechowywanie danych w Europie – pod warunkiem zawarcia odpowiedniej umowy.
Jeśli lokalizacja danych ma dla Twojej firmy istotne znaczenie – np. ze względu na RODO lub wewnętrzne wymogi zgodności – warto rozważyć korzystanie z Azure OpenAI. W tym wariancie modele OpenAI są uruchamiane w chmurze Microsoftu, a Ty możesz wybrać konkretny region, np. Europę Zachodnią lub Azję, zapewniając, że dane będą przetwarzane i przechowywane wyłącznie w wybranej lokalizacji.
Więcej o Azure przeczytasz w kolejnej części – ale w skrócie: OpenAI zapewnia bezpieczne przetwarzanie danych, jednak jeśli zależy Ci na pełnej kontroli nad ich lokalizacją, lepszym wyborem może być chmurowy partner, taki jak Azure.
Gemini – Podejście Google do Twoich danych
Google rozwija generatywną sztuczną inteligencję m.in. poprzez model Gemini – nowej generacji rozwiązanie, które zasila produkty takie jak chatbot Google Gemini oraz różne usługi AI dostępne w Google Cloud. Oto jak Google podchodzi do kwestii Twoich danych:
Aplikacja Gemini
Domyślnie Google zapisuje historię czatów z Gemini na Twoim koncie (podobnie jak historię wyszukiwania) i może wykorzystywać te dane do ulepszania swoich usług. Użytkownik ma jednak możliwość zarządzania tym ustawieniem za pomocą funkcji „Gemini Activity”.
Aby to skonfigurować:
- Przejdź do ustawień Gemini Activity,
- Wstrzymaj Gemini Activity, aby zatrzymać zapisywanie rozmów i uniemożliwić ich wykorzystanie jako źródła danych do trenowania modeli AI.
- Możesz także usunąć dotychczasową historię konwersacji.
Wyłączenie Aktywności Gemini oznacza, że nowe rozmowy nie będą wykorzystywane do ulepszania usług opartych na uczeniu maszynowym ani przeglądane przez członków zespołu Google – chyba że samodzielnie prześlesz je jako opinię. Daje to zwykłym użytkownikom możliwość rezygnacji z udziału w trenowaniu modeli, podobnie jak opcja opt-out dostępna w ChatGPT.
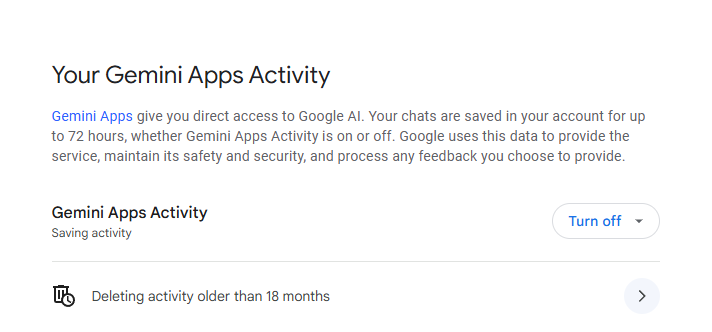
Aby zatrzymać zapisywanie rozmów, przejdź do zakładki Activity i wyłącz opcję Gemini Apps Activity. Możesz również usunąć wcześniejsze konwersacje.
API i Vertex AI
Jeśli korzystasz z platformy Vertex AI w Google Cloud:
- Twoje prompty i odpowiedzi nie są wykorzystywane do trenowania modeli AI bez Twojej wyraźnej zgody.
- Dane mogą być tymczasowo buforowane (do 24 godzin) w celu poprawy wydajności, ale pozostają w wybranym przez Ciebie regionie geograficznym.
- Firmy mogą zdecydować się na politykę braku retencji danych (zero-retention), aby zapewnić maksymalny poziom prywatności.
Lokalizacja danych
Lokalizacja danych to mocna strona Google – możesz samodzielnie wybrać region geograficzny, w którym działa Twoja usługa AI (np. centra danych w UE lub USA), a Google będzie przetwarzać i przechowywać dane właśnie w tym regionie, spełniając wymagania dotyczące lokalizacji danych.
Microsoft Azure OpenAI - Domyślna ochrona prywatności danych
Zasady trenowania modelu
Usługa Azure OpenAI firmy Microsoft umożliwia firmom korzystanie z modeli OpenAI za pośrednictwem zaufanej platformy chmurowej Azure. Prywatność jest tutaj jednym z głównych atutów. Microsoft wyraźnie zaznacza: wszelkie dane przesyłane do Azure OpenAI nie są wykorzystywane do trenowania modeli ani do ulepszania usług Microsoftu czy OpenAI.
Usługa Azure OpenAI w praktyce hostuje modele OpenAI (GPT-4, GPT-3.5 itd.) w infrastrukturze chmurowej Microsoft Azure. Microsoft zaprojektował tę usługę specjalnie z myślą o przedsiębiorstwach, które wymagają silnych mechanizmów ochrony prywatności. Do kluczowych elementów należą:
Wszelkie dane wprowadzone do usługi Azure OpenAI – takie jak prompty, odpowiedzi modeli (completions), osadzenia (embeddings) czy dane do fine-tuningu – nie są wykorzystywane do trenowania modeli AI.
Twoje dane wejściowe i wyjściowe „nie są dostępne dla innych klientów, nie są udostępniane OpenAI i nie są wykorzystywane do ulepszania modeli OpenAI”.
Microsoft przechowuje dane jedynie w zakresie niezbędnym do świadczenia usługi i monitorowania nadużyć. Domyślnie prompty i odpowiedzi są przechowywane tymczasowo (do 30 dni) wyłącznie w celu wykrywania nadużyć, po czym są usuwane.
Jeśli nawet to tymczasowe przechowywanie stanowi problem (np. w przypadku danych o wysokiej wrażliwości), Microsoft oferuje procedurę zwaną „modified abuse monitoring”, która umożliwia całkowite pominięcie 30-dniowego przechowywania. Oznacza to, że żadne prompty nie są w ogóle zapisywane. Zazwyczaj wymaga to zatwierdzenia, ale jest to możliwe w scenariuszach o podwyższonym poziomie bezpieczeństwa.
Lokalizacja danych
Ponieważ usługa działa w środowisku Azure, możesz łatwo wybrać region i spełnić wymagania dotyczące lokalizacji danych. Podczas konfigurowania Azure OpenAI wybierasz region, w którym zostanie wdrożona usługa (np. Wschodnie USA, Europa Zachodnia, Azja Południowo-Wschodnia itd.). Całe przetwarzanie i przechowywanie danych na potrzeby wnioskowania (inference) odbywa się w wybranym regionie lub w jego granicach geograficznych.
Oznacza to, że jeśli wdrożysz usługę w Europie Zachodniej, Twoje dane nie opuszczą Europy – co ma kluczowe znaczenie dla zgodności z RODO. Sama platforma Azure spełnia szereg standardów zgodności (takich jak SOC 2, ISO 27001 itp.), a certyfikacje te obejmują również usługę Azure OpenAI jako część oferty Azure.
Anthropic (Claude) – Asystent AI z priorytetem prywatności
Zasady trenowania modelu
Anthropic, firma stojąca za asystentem AI Claude (Claude 2 i nowsze wersje), od początku kładzie duży nacisk na podejście zorientowane na prywatność. Stosuje model działania oparty na zgodzie użytkownika (opt-in):
Domyślnie Anthropic nie wykorzystuje Twoich rozmów ani danych do trenowania swoich modeli. Dotyczy to zarówno oferty komercyjnej (Claude for Work, Anthropic API), jak i produktów konsumenckich (Claude Free, Claude Pro) – Twoje prompty oraz odpowiedzi Claude’a nie są automatycznie używane do trenowania modeli.
Dane są wykorzystywane wyłącznie wtedy, gdy świadomie wyrazisz na to zgodę – na przykład przesyłając opinię. Jeśli klikniesz ikonę kciuka w górę lub w dół w interfejsie Claude’a albo prześlesz dane przez kanał feedbacku, oznacza to, że wyrażasz zgodę: „you can learn from this”.
Dla klientów biznesowych Anthropic oferuje rozwiązania Claude Team/Enterprise, które nie tylko gwarantują, że dane nie są wykorzystywane do trenowania modeli, ale także udostępniają funkcje kontroli administracyjnej. Jedną z nich są niestandardowe ustawienia dotyczące retencji danych.
Domyślnie systemy Anthropic mogą przechowywać dane wejściowe i wyjściowe bezterminowo na potrzeby konta (ale nie do trenowania modeli). Jednak administratorzy usługi Claude Enterprise mogą ustawić własną politykę retencji – na przykład usuwanie wszystkich danych rozmów po 30, 60 dniach itd., przy czym aktualne minimum to 30 dni.
Takie mechanizmy kontroli mają na celu wspieranie zgodności z przepisami takimi jak RODO.
Lokalizacja danych
Anthropic to stosunkowo nowy gracz na rynku, i obecnie – korzystając bezpośrednio z ich API – nie masz możliwości jawnego wyboru regionu przechowywania danych. Najprawdopodobniej dane są hostowane w USA przez Anthropic lub za pośrednictwem dostawców chmurowych, takich jak AWS, w regionie amerykańskim.
Jednak modele Anthropic są również dostępne za pośrednictwem partnerów, co może pomóc w spełnieniu wymagań dotyczących lokalizacji danych. Przykładowo, Claude firmy Anthropic jest oferowany przez usługę Amazon Bedrock (AI-as-a-service od AWS) oraz przez Google Cloud Vertex AI. Korzystając z Claude’a za pośrednictwem jednej z tych platform, możesz skorzystać z możliwości wyboru regionu oferowanych przez AWS lub Google.
Podsumowanie
Zrozumienie praktyk związanych z gromadzeniem danych przez dostawców dużych modeli językowych (LLM) ma kluczowe znaczenie dla zgodności z przepisami, zaufania klientów oraz ładu informacyjnego w organizacji. Niezależnie od tego, czy priorytetem jest zgodność z regulacjami, transparentność wobec klientów czy wewnętrzne zarządzanie danymi – poniższe informacje pomogą w podjęciu świadomych decyzji. Wybieraj dostawców, którzy są zgodni z Twoimi standardami prywatności – i zawsze weryfikuj ustawienia swoich usług.
Oto porównanie najważniejszych platform:
| Dostawca | Domyślne trenowanie na danych | Ustawienia w aplikacji webowej | Opcje lokalizacji danych | Zgodność z RODO/CCPA | Polityka prywatności |
|---|---|---|---|---|---|
| OpenAI | Nie (API) | Dostępna opcja opt-out | Nie (chyba że przez Azure Microsoft) | Tak | Prywatność konsumencka |
| Nie (Cloud + Gemini) | Brak trenowania domyślnie | Szeroka kontrola regionalna | Tak | Prywatność korporacyjna, Prywatność Gemini, Vertex AI | |
| Azure | Nie | Nie dotyczy | Pełna kontrola regionalna | Tak | Prywatność Azure i OpenAI |
| Anthropic | Nie | Brak trenowania domyślnie | Nie (chyba że przez partnerów) | Tak | Użytkownicy API, Użytkownicy Claude.ai |
Dla maksymalnej prywatności i pełnej kontroli alternatywą pozostaje lokalne wdrożenie modeli (on-premises). Pozwala to całkowicie wyeliminować obawy związane z przechowywaniem danych w chmurze. Więcej na temat lokalnego wdrażania przeczytasz tutaj.