

Ever wondered where your data goes when you interact with AI cloud platforms? Or is it used to train future models? In this article, we’ll break down the data privacy policies of top AI platforms. You will also learn what to do to ensure your data is not used for training Large Language Models (LLM).
Major AI cloud providers have become increasingly transparent about their data usage policies – especially when it comes to training models. While most platforms, particularly those offering enterprise-level services, do not use your inputs and outputs for training by default, the fine print matters. Understanding how these services handle your data – and how you can maintain control – is essential.
In this article, we’ll break down the data privacy and model training policies of top AI platforms, including OpenAI, Google Gemini, Microsoft’s Azure OpenAI and Anthropic’s Claude. You’ll learn:
- How AI platforms use your data and whether your data is used to train models by default
- How to prevent AI from using your data opt, if needed
- Where your data is stored (data residency), and
- What compliance measures (like GDPR) apply
Adopting AI isn’t just about prompt engineering or model performance. It’s also about knowing where your data goes—and how to ensure it stays under your control.
Here’s what you need to know:
OpenAI – Data Usage and Privacy
OpenAI treats your data differently based on how you interact with its services:
ChatGPT App (Web/Mobile)
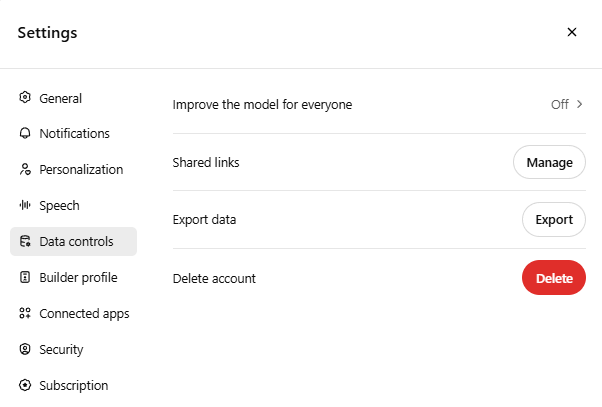
When you chat with ChatGPT, your conversations may be used to train AI models – unless you manually opt out. To prevent your data from being used:
- Go to Settings → Data Controls → Improve the model for everyone and toggle it off.
- Even with the opt-out, OpenAI stores chats for 30 days for abuse monitoring before deletion.
OpenAI API and ChatGPT Enterprise
If you’re a developer or a business using OpenAI’s API or ChatGPT Enterprise, there’s no need to opt out. By default, OpenAI does not use API or Enterprise data to train its models, and your data stays private. You don’t need to do anything to opt out – it’s already protected. You can choose to share data to help improve the model, but only if you want to.
Data Residency
OpenAI’s servers are mostly based in the United States, and currently, if you’re using the API directly, you can’t choose where your data is stored. That means your data is processed within OpenAI’s own infrastructure – protected by strong security, but not necessarily hosted in your country.
However, there’s some progress for enterprise users. OpenAI recently introduced an option for eligible enterprise API customers that allows data to be stored in Europe, provided there’s a specific agreement in place.
If regional data residency is important for your business – say, for GDPR or internal compliance – you might want to consider using Azure OpenAI, which hosts OpenAI’s models on Microsoft’s cloud. With Azure, you can choose a region like Western Europe or Asia, and all data processing and storage will stay within that geography.
We’ll dive into Azure more in the next section – but in short: OpenAI handles your data securely, but for strict control over where it lives, a partner cloud service like Azure may be a better fit.
Google (Gemini) – Google’s Approach to Your Data
Google’s foray into generative AI includes Gemini, a next-generation model that powers products like Google Gemini (the chatbot) and various enterprise AI offerings on Google Cloud. Here’s how they handle your data:
Gemini App
By default, Google does save your Gemini chat history to your account (much like search history) and may use it to improve their service. However, Google provides a “Gemini Activity” setting to control this.
To manage this:
- Visit Gemini Activity settings.
- Pause Gemini Activity to stop saving chats and prevent them from being used in AI model training data sources.
- You can also delete existing conversation history.
Turning off Gemini Activity means your new chats won’t be used to improve their machine learning services, nor will they be seen by human reviewers, unless you explicitly submit them as feedback. This gives regular users a way to opt out, similar to ChatGPT’s opt-out toggle.
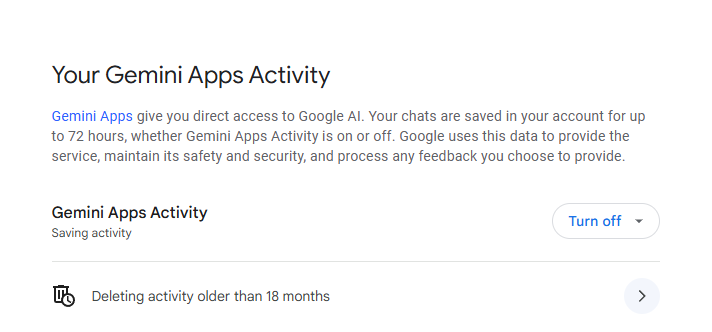
To stop saving your conversations, go to the Activity tab and toggle Gemini Apps Activity. You can also delete your past conversations.
API and Vertex AI
If you’re using Google Cloud’s Vertex AI platform:
- Your prompts and outputs are not used to train AI models without explicit permission.
- Data may be cached briefly (up to 24 hours) for performance but remains within your selected geographic region.
- Businesses can opt for a zero-retention policy for maximum privacy.
Data residency
Data residency is a strong point for Google: you can choose which geographic region your AI service runs in (e.g. EU or US data centers), and Google will process and store data in that region to meet any data localization requirements.
Microsoft Azure OpenAI – Enterprise Data Protection by Design
Training Policy
Microsoft’s Azure OpenAI Service lets companies use OpenAI’s models through the trusted Azure cloud platform. Privacy is a major selling point here. Microsoft is very explicit: any data you send into Azure OpenAI is not used to train the underlying models or improve Microsoft’s or OpenAI’s services .
Microsoft’s Azure OpenAI Service essentially hosts OpenAI’s models (GPT-4, GPT-3.5, etc.) within the Microsoft Azure cloud. Microsoft has specifically designed this service for enterprises that require strong privacy protections. Key aspects are:
- Any data you input into Azure OpenAI – prompts, completions (model outputs), embeddings, fine-tuning data – is not used to train the AI models.
- Your inputs and outputs “are NOT available to other customers, are NOT available to OpenAI, and are NOT used to improve OpenAI models”.
- Microsoft only retains data as needed to provide the service and monitor for misuse. In fact, prompts and outputs on Azure are stored only temporarily (up to 30 days) by default, and solely for abuse detection purposes. After 30 days, those prompts are deleted. If even this temporary storage is a concern (say, for ultra-sensitive data), Microsoft offers a process called “modified abuse monitoring” where you can request that even the 30-day storage be bypassed, meaning no prompts are retained at all. Typically, you’d need approval for this exception, but it’s an option for high-security scenarios.
Data Residency
Because it’s on Azure, you also benefit from easily choosing the region and complying with data residency requirements. When setting up Azure OpenAI, you deploy the service to an Azure region (for example, East US, West Europe, Southeast Asia, etc.). All processing and data storage for inference will occur within that region or its geographical boundary. So, if you deploy in Western Europe, your data isn’t leaving Europe – crucial for GDPR compliance. Azure itself meets numerous compliance standards (SOC 2, ISO 27001, etc.), and these extend to Azure OpenAI as an Azure service.
Anthropic (Claude) – A Privacy-First AI Assistant
Training Policy
Anthropic, the company behind the Claude AI assistant (Claude 2 and newer versions), has emphasized a privacy-conscious approach from the outset. Anthropic adopts an opt-in approach:
- By default, Anthropic does not use your conversations or data to train its models. This applies to both their commercial offerings (Claude for Work, Anthropic API) and consumer products (Claude Free, Claude Pro) – your prompts and Claude’s responses aren’t automatically used for model training.
- They only use data if you deliberately opt-in, such as by providing explicit feedback. For instance, if you click a thumbs-up/down in a Claude interface or send data to their feedback channels, you’re essentially saying “you can learn from this”.
For enterprise clients, Anthropic offers Claude Team/Enterprise, which not only guarantees no training on your data but also provides admin controls. One such feature is custom data retention settings. By default, Anthropic’s systems might retain your inputs/outputs indefinitely for your account (though not for training). However, Claude Enterprise admins can set a retention policy – for example, you might set it to delete all conversation data after 30 days, 60 days, etc., with 30 days being the current minimum. These controls aim to support compliance with regulations like GDPR.
Data Residency
Anthropic is a newer player, and currently, when you use their API directly, you don’t explicitly choose a data region – it’s likely hosted in the US by Anthropic (or possibly through cloud providers like AWS in the US region). However, Anthropic models are also available through partners, which can help with data residency. For example, Anthropic’s Claude is offered via Amazon Bedrock (AWS’s AI service) and via Google Cloud Vertex AI. If you use Claude through one of these platforms, you can take advantage of AWS’s or Google’s region controls.
Conclusion
Understanding the data collection practices of LLM providers is crucial for AI compliance, customer trust, and corporate governance. Whether you’re focused on compliance, customer trust, or internal data governance, these insights help you make informed decisions. Choose providers that align with your privacy values – and always review your settings.
Here’s a comparison of major platforms:
| Provider | Default Data Training | Web App Setting | Data Residency Options | GDPR/CCPA Compliance | Privacy Policy |
|---|---|---|---|---|---|
| OpenAI | No (API) | Opt-out available | No; (unless used via Azure Microsoft) | Yes | Consumer privacy |
| No (Cloud + Gemini) | No training by default | Broad region control | Yes | Enterprise privacy, Gemini privacy, Vertex AI | |
| Azure | No | N/A | Full regional control | Yes | Azure, OpenAI privacy |
| Anthropic | No | No training by default | No (unless used via partners) | Yes | API users, Claude.ai users |
For maximum privacy and control, local deployment (on-premises models) is always an alternative. This avoids cloud storage concerns entirely. You can read more about local deployment here.